|
|

TechSEO360 Guide on Website and SEO Audits
Analyzing your own website is often the first thing to do in any SEO audit. Here is a step-by-step guide.
Note: We have a video tutorial:

Overview of TechSEO360
Our software comes with a wide arsenal of tools, and this article will show how to use most of these for various website and SEO auditing tasks.
You can skip ahead directly to specific parts of this article:
You can skip ahead directly to specific parts of this article:
- Getting Started - Scan Website
- Quick Reports
- Controlling Visible Data Columns
- Discover Internal Linking Errors
- See Line Numbers, Anchor Texts and Follow / Nofollow for All Links
- See Which Images Are Referenced Without "alt" Text
- Understand Internal Navigation and Link Importance
- See All Redirects, Canonical, NoIndex and Similar
- Check for Duplicate Content
- Optimize Pages for Better SEO Including Title Sizes
- Custom Search Website for Text and Code
- View The Most Important Keywords in All Website Content
- Generate and Manage Keyword Lists
- Spell Check Entire Websites
- Validate HTML and CSS of All Pages
- Integration With Online Tools
- Crawl Sites Using a Custom User Agent ID and Proxy
- Import List of URLs and Log Files for Further Analysis
- Export Data to HTML, CSV and Tools Like Excel
- How to Create Sitemaps
- See URLs with AJAX Fragments and Content
- Windows, Mac and Linux
Getting Started - Scan Website
The first screen you see is where you can type in the
website address and start the crawl:

Per default most of the advanced options are hidden, and the software will use its default settings.
However, if you want to change the settings, e.g. to collect more data or increase the crawl speed by increasing the number of max connections, you can make all the options visible by switching off Simplified easy mode.
In the screenshot below, we have turned up worker threads and simultaneous connections to the max:

Per default most of the advanced options are hidden, and the software will use its default settings.
However, if you want to change the settings, e.g. to collect more data or increase the crawl speed by increasing the number of max connections, you can make all the options visible by switching off Simplified easy mode.
In the screenshot below, we have turned up worker threads and simultaneous connections to the max:
Quick Reports
This dropdown shows a list of predefined "quick reports" that can be used after scanning a website.

These predefined reports configures the following options:
You can also set all these manually to create your own custom reports. This guide includes various example of this as you read through it.
These predefined reports configures the following options:
- Which data columns are visible
- Which "quick filter options" are active.
- The "quick filter text".
- Activates quick filtering.
You can also set all these manually to create your own custom reports. This guide includes various example of this as you read through it.
Controlling Visible Data Columns
Before we do further analysis post-scan of the website,
we need to know how to switch-on and switch-off data columns
since seeing them all at once can be a little overwhelming.
The image below shows where you can hide and show columns.

You may also want to enable or disable the following options:
The image below shows where you can hide and show columns.
You may also want to enable or disable the following options:
- View | Allow big URL lists in data columns
- View | Allow relative paths inside URL lists in data columns
- View | Only show page URLs inside URL lists in data columns
Discover Internal Linking Errors
When checking for errors on a new
website, it can often be fastest to use quick filters.
In our following example, we
are using the option Only show URLs with filter-text found in "response code" columns,
combined with "404" as filter text and clicking the filtering icon.
By doing above, we get a list of URLs with response code 404 as shown here:

If you select a 404 URL at the left side, you can at the right see details of how and where it was discovered. You can see all URLs that linked, used (usually the src attribute in HTML tags) or redirected to the 404 URL.
Note: To also have external links checked, enable these options:
If you want to use this for exports (explained later below) you can also enable columns that will show you the most important internal backlinks and anchor texts.

By doing above, we get a list of URLs with response code 404 as shown here:
If you select a 404 URL at the left side, you can at the right see details of how and where it was discovered. You can see all URLs that linked, used (usually the src attribute in HTML tags) or redirected to the 404 URL.
Note: To also have external links checked, enable these options:
- Scan website | Data collection | Store found external links option
- Scan website | Data collection | Verify external URLs exist (and analyze if applicable)
If you want to use this for exports (explained later below) you can also enable columns that will show you the most important internal backlinks and anchor texts.
See Line Numbers, Anchor Texts and Follow / Nofollow for All Links
For all links found in the website scanned, it is possible to see the following information:

To ensure nofollow links are included during website crawling, uncheck the following options in Scan website | Webmaster filters:
- The line number in the page source where the link resides.
- The anchor text associated to the link.
- If the link is follow or nofollow
To ensure nofollow links are included during website crawling, uncheck the following options in Scan website | Webmaster filters:
- Obey meta tag "robots" nofollow
- Obey a tag "rel" nofollow
See Which Images Are Referenced Without "alt" Text
When using images in websites, it is often an advantage to use markup that describes them,
i.e. use the
For this you can use the built-in report called Show only images where some "linked-by" or "used-by" miss anchors / "alt". This report will list all images that are:
It achieves this by:
When viewing results, you can in extended details see where each image is referenced without one of above mentioned text types. In the screenshot below, we are inspecting the used by data which originate from sources like

alt attribute in the <img> HTML tag.
For this you can use the built-in report called Show only images where some "linked-by" or "used-by" miss anchors / "alt". This report will list all images that are:
- Used without an alternative text
- Linked without an anchor text.
It achieves this by:
- Only showing relevant data columns.
- Enable filter: Only show URLs that are images.
- Enable filter: Only show URLs where "linked-by" or "used-by" miss anchors or "alt".
When viewing results, you can in extended details see where each image is referenced without one of above mentioned text types. In the screenshot below, we are inspecting the used by data which originate from sources like
<img src="example.webp" alt="example">.
Understand Internal Navigation and Link Importance
Understanding how your internal website structures helps search engines and
humans find your content can be very useful.
To see how many clicks it takes for a human to reach a specific page from the front page, use the data column clicks to navigate.
While PageRank sculpting is mostly a day of the past, your internal links and the link juice passed around still help search engines understand what content and pages you find to be the most important within your website.
Our software automatically calculates importance scores for all URLs using these steps:

You can affect the algorithm through the menu options:
To include nofollow links (which are given significantly lower weight than follow links) uncheck these options in Scan website | Webmaster filters:
Humans
To see how many clicks it takes for a human to reach a specific page from the front page, use the data column clicks to navigate.
Search engines
While PageRank sculpting is mostly a day of the past, your internal links and the link juice passed around still help search engines understand what content and pages you find to be the most important within your website.
Our software automatically calculates importance scores for all URLs using these steps:
- There is given more weight to links found on pages with many incoming links.
- The link juice a page can pass on will be shared among its outgoing links.
- The scores are converted to a logarithmic base and scaled to 0...10.
You can affect the algorithm through the menu options:
- Tools | Importance algorithm option: Links "reduce": Weights repeated links on the same page less and less. Weights links placed further down in content less and less.
- Tools | Importance algorithm option: Links "noself": Ignore links going to the same page as the link is located at.
To include nofollow links (which are given significantly lower weight than follow links) uncheck these options in Scan website | Webmaster filters:
- Obey meta tag "robots" nofollow
- Obey a tag "rel" nofollow
See All Redirects, Canonical, NoIndex and Similar
It is possible to see site-wide information on which URLs and pages that are:
Above data is mainly retrieved from meta tags, HTTP headers and program analysis of URLs.
To see all the data, finish the website scan and enable visibility of these columns:

Notice that we in the above screenshot have switched off tree view and instead see all URLs in list view mode.
To set up a comprehensive filter that shows all pages that redirect in any way:
This configures the filters so URLs are only shown if they match the following conditions:
- HTTP Redirects.
- Meta refresh redirects.
- Excluded by robots.txt.
- Marked canonical pointing to itself, canonical pointing to another URL than itself, noindex or nofollow, noarchive, nosnippet.
- Duplicates of some sort, e.g. index or missing slash page URLs.
- And more..
Above data is mainly retrieved from meta tags, HTTP headers and program analysis of URLs.
To see all the data, finish the website scan and enable visibility of these columns:
- Core data | Path
- Core data | Response code
- Core data | URL content state flags detected
- URL references | Redirects count
- URL references | Redirects to path
- URL references | Redirects to response code
- URL references | Redirects to path (final)
- URL references | Redirects to response code (final)
(This in particular is useful in making sure your redirect destinations are setup correctly.)
Notice that we in the above screenshot have switched off tree view and instead see all URLs in list view mode.
To set up a comprehensive filter that shows all pages that redirect in any way:
-
First enable options:
- View | Data filter options | Only show URLs with all [filter-text] found in "URL state flags" column
- View | Data filter options | Only show URLs with any filter-text-number found in "response code" column
- View | Data filter options | Only show URLs that are pages
- After that use the following as the quick filter text:
[httpredirect|canonicalredirect|metarefreshredirect] -[noindex] 200 301 302 307
This configures the filters so URLs are only shown if they match the following conditions:
- The URL has to be a page - can not e.g. be an image.
- The URL has to either HTTP redirect or meta refresh or canonical point to another page.
- The URL can not contain a noindex instruction.
- The URL HTTP response code has to be either 200, 301, 302 or 307.
Check for Duplicate Content
Duplicate Page Titles, Headers etc.
It is generally a bad idea to have multiple pages share the same duplicate title, headers and descriptions. To find such pages, you can use the quick filter feature after the initial website crawl has finished.
In the screenshot below, we have limited our quick filter to only show pages with duplicate titles that also contain the string "the game" in one of its data columns.

Duplicate Page Content
Some tools can perform a simple MD5 hash check of all pages in a website. However, that will only tell you of pages that are 100% the same which is not very likely to happen on most websites.
Instead, TechSEO360 can sort and and group pages with similar content. In addition, you can see a visual representation of the most prominent page elements. Together, this makes a useful combination for finding pages that may have duplicate content. To use this:
- Enable option Scan website | Data collection | Perform keyword density analysis of all pages before you scan the website.
- Enable visibility of data column Page Content Similarity.

Before starting a site scan, you can increase the accuracy by setting the following options in Analyze Website | Keyword analysis.
- Set Select stop words to match the main language of your website or select auto if it uses multiple languages.
- Set Stop words usage to Removed from content.
- Set Site analysis | Max words in phrase to 2.
- Set Site analysis | Max results per count type to a higher value than the default, e.g. 40.
Note: If you use multiple languages in your website, read this about how page language detection works in TechSEO360.
Duplicate URLs
Many websites contain pages that can be accessed from multiple unique URLs. Such URLs should redirect or otherwise point search engines to the primary source. If you enable visibility of the data column Crawler flags, you can see all page URLs that:
- Explicitly redirect or point to other URLs using canonical, HTTP redirect or meta refresh.
- Are similar to other URLs, e.g. example/dir/, example/dir and example/dir/index.html. For these, the primary and duplicate URLs are calculated and shown based on HTTP response codes and internal linking.
Optimize Pages for Better SEO Including Title Sizes
For those who want to do on-page SEO of all pages, there is a built-in report which will show you the most important data columns including:

Note: It is possible to filter the data in various ways - e.g. so you only see pages where titles are too long to be shown in search results.
- Word count in page content.
- Text versus code percentage.
- Title and description length in characters.
- Title and description length in pixels.
- Internal linking and page scores.
- Clicks on links required to reach a page from the domain root.
Note: It is possible to filter the data in various ways - e.g. so you only see pages where titles are too long to be shown in search results.
Custom Search Website for Text and Code
Before you start the initial website scan, you can configure
various text/code patterns you want to search for as pages are analyzed and crawled.
You can configure this in Scan website | Data collection, and it is possible to use both pre-defined patterns and make your own. This can be very useful to see if e.g. Google Analytics has been installed correctly on all pages.
Notice that we have to name each our search patterns, so we later can distinguish among them.
In our screenshot, we have a pattern called ga_new that searches for Google Analytic using a regular expression. (If you do not know regular expressions, simply writing a snippet of the text or code you want to find will often work as well.)
When adding and removing patterns, be sure you have added/removed them from the dropdown list using the [+] and [-] buttons.

After the website scan has finished, you will be able to see how many times each added search pattern was found on all pages.

You can configure this in Scan website | Data collection, and it is possible to use both pre-defined patterns and make your own. This can be very useful to see if e.g. Google Analytics has been installed correctly on all pages.
Notice that we have to name each our search patterns, so we later can distinguish among them.
In our screenshot, we have a pattern called ga_new that searches for Google Analytic using a regular expression. (If you do not know regular expressions, simply writing a snippet of the text or code you want to find will often work as well.)
When adding and removing patterns, be sure you have added/removed them from the dropdown list using the [+] and [-] buttons.
After the website scan has finished, you will be able to see how many times each added search pattern was found on all pages.
View The Most Important Keywords in All Website Content
It is possible to extract the top words of all pages during site crawl.
To do so, tick option Scan website | Data collection | Perform keyword density analysis of all pages.
The algorithm that calculates keyword scores takes the following things into consideration:
The scores you see are formatted in a way that is readable to humans, but which is also easy to do further analysis on by custom scripts and tools. (Which is useful if you want to export the data.)

If you rather get a detailed breakdown of keywords on single pages, you can get that as well:

This is also where you can configure how keywords scores are calculated. To learn more about this, view the A1 Keyword Research help page about on-page analysis of keywords.
To do so, tick option Scan website | Data collection | Perform keyword density analysis of all pages.
The algorithm that calculates keyword scores takes the following things into consideration:
- Tries to detect language and apply the correct list of stop words.
- The keyword density in the complete page text.
- Text inside important HTML elements has more importance than normal text.
The scores you see are formatted in a way that is readable to humans, but which is also easy to do further analysis on by custom scripts and tools. (Which is useful if you want to export the data.)
If you rather get a detailed breakdown of keywords on single pages, you can get that as well:
This is also where you can configure how keywords scores are calculated. To learn more about this, view the A1 Keyword Research help page about on-page analysis of keywords.
Generate and Manage Keyword Lists
If you ever need to create or maintain keyword lists, TechSEO360 comes built-in with powerfull keyword tools you can use to generate, combine and clean keyword lists.
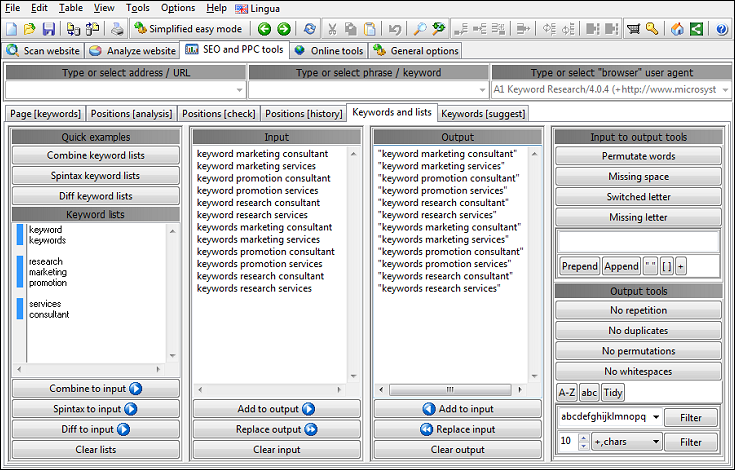
Spell Check Entire Websites
If you in Scan website | Data collection
choose to do spell
checking, you can also see the number of spelling errors for all pages after
the crawl has finished.
To see the specific errors, you can view the source code of the followed by using clicking Tools | Spell check document.

As can be seen, the dictionary files in can not include everything, so you will often benefit from making a preliminary scan where you add common words specific for your website niche to the dictionary.

To see the specific errors, you can view the source code of the followed by using clicking Tools | Spell check document.
As can be seen, the dictionary files in can not include everything, so you will often benefit from making a preliminary scan where you add common words specific for your website niche to the dictionary.
Validate HTML and CSS of All Pages
TechSEO360 can use multiple different HTML/CSS
page checkers including W3C/HTML, W3C/CSS, Tidy/HTML,
CSE/HTML and CSE/CSS.
Since HTML/CSS validation can slow website crawls, these options are unchecked by default.
List of options used for HTML/CSS validation:
When you have finished a website scan with HTML/CSS validation enabled, the result will look similar to this:

Since HTML/CSS validation can slow website crawls, these options are unchecked by default.
List of options used for HTML/CSS validation:
- Scan website | Data collection | Enable HTML/CSS validation
- General options and tools | Tool paths | TIDY executable path
- General options and tools | Tool paths | CSE HTML Validator command line executable path
- Scan website | Data collection | Validate HTML using W3C HTML Validator
- Scan website | Data collection | Validate CSS using W3C CSS Validator
When you have finished a website scan with HTML/CSS validation enabled, the result will look similar to this:
Integration With Online Tools
To ease the day-to-day work flow, the software has a separate tab with various 3rd party online tools.
Depending on the URL selected and data available, you can select one of the online tools in the drop down list, and the correct URL including query parameters will automatically be opened in an embedded browser.

Depending on the URL selected and data available, you can select one of the online tools in the drop down list, and the correct URL including query parameters will automatically be opened in an embedded browser.
Crawl Sites Using a Custom User Agent ID and Proxy
Sometimes it can be useful to hide user agent ID
and IP address used when crawling websites.
Possible reasons can be if a website:
You can configure these things in General options and tools | Internet crawler.

Possible reasons can be if a website:
- Returns different content for crawlers than humans, i.e. website cloaking.
- Uses IP address ranges to detect country followed by redirecting to a another page/site.
You can configure these things in General options and tools | Internet crawler.
Import Data from 3rd Party Services
You can import URLs and extended data from 3rd parties through the menu File | Import URLs from text/log/csv.
Depending on what you import, all the URLs will be placed in either the internal or external tabs.
Importing can be used for both adding more information to existing crawl data and for seeding new crawls.
There is additional data imported when the source data originates from:
To start a website crawl from the imported URLs you can:
To crawl the imported URLs in the external tab, tick options:
Depending on what you import, all the URLs will be placed in either the internal or external tabs.
Importing can be used for both adding more information to existing crawl data and for seeding new crawls.
There is additional data imported when the source data originates from:
- Apache server logs:
- Which pages have been accessed by GoogleBot. This is shown by [googlebot] in data column URL Flags.
- Which URLs that are not internally linked or used. This is shown by [orphan] in data column URL Flags.
- Google Search Console CSV exports:
- Which pages are indexed by Google. This is shown by [googleindexed] in data column URL Flags.
- Clicks of each URL in Google Search Results - this is shown in data column Clicks.
- Impressions of each URL in Google Search Results - this is shown in data column Impressions.
- Majestic CSV exports:
- Link score of all URLs - this is shown in data column Backlinks score. When available the data is used to further improve calculations behind the data columns Importance score calculated and Importance score scaled.
To start a website crawl from the imported URLs you can:
- Check option Scan website | Recrawl.
- Check option Scan website | Recrawl (listed only) - this will avoid including any new URLs to analysis queue and results output.
To crawl the imported URLs in the external tab, tick options:
- Scan website | Data collection | Store found external links option
- Scan website | Data collection | Verify external URLs exist (and analyze if applicable)
Export Data to HTML, CSV and Tools Like Excel
Generally speaking, you can export the content of
any data control by focusing/clicking it followed
by using the
File | Export selected data to file...
or
File | Export selected data to clipboard...
menu items.
The default is to export data as standard .CSV files, but in-case the program you intend to import the .CSV files into have specific needs, or if you would like to have e.g. column headers listed as well, you can adjust settings in menu File | Export and import options.
The data you will usually export is found in the main view. Here you can create custom exports and reports that contain just the information you need. Just select which columns are visible activate the quick filters you want (e.g. only 404 not found errors, duplicate titles or similar) before exporting.
Alternatively, you can also use the built-in reporting buttons that contains various configuration presets:
Note: You can create many more data views if you learn how to configure filters and visible columns.
The default is to export data as standard .CSV files, but in-case the program you intend to import the .CSV files into have specific needs, or if you would like to have e.g. column headers listed as well, you can adjust settings in menu File | Export and import options.
The data you will usually export is found in the main view. Here you can create custom exports and reports that contain just the information you need. Just select which columns are visible activate the quick filters you want (e.g. only 404 not found errors, duplicate titles or similar) before exporting.
Alternatively, you can also use the built-in reporting buttons that contains various configuration presets:
Note: You can create many more data views if you learn how to configure filters and visible columns.
How to Create Sitemaps
Use the Quick presets... button to optimize your crawl - e.g. to create a video sitemap for a website with externally hosted videos.
Afterwards, just click the Start scan button to initiate a website crawl.

When the website scan has finished, pick the sitemap file kind you want to create and click the Build selected button.

You can find a complete list of tutorials for each sitemap file kind in our online help.
Afterwards, just click the Start scan button to initiate a website crawl.
When the website scan has finished, pick the sitemap file kind you want to create and click the Build selected button.
You can find a complete list of tutorials for each sitemap file kind in our online help.
See URLs with AJAX Fragments and Content
Quick explanation of fragments in URLs:
Before website scan:
After website scan:

-
Page-relative-fragments:
Relative links within a page:
http://example.com/somepage#relative-page-link -
AJAX-fragments:
client-side Javascript that queries
server-side code and replaces content-in-browser:
http://example.com/somepage#lookup-replace-data
http://example.com/somepage#!lookup-replace-data -
AJAX-fragments-Google-initiative: Part of the Google initiative
Making AJAX Applications Crawlable:
http://example.com/somepage#!lookup-replace-data
This solution has since been deprecated by Google themselves.
Before website scan:
-
Hash fragments
#are stripped when using default settings. To change this, uncheck:- In Scan website | Crawler Options | Cutout "#" in internal links
- In Scan website | Crawler Options | Cutout "#" in external links
-
Hashbang fragments
#!are always kept and included. -
If you want to analyze AJAX content fetched immediately after the initial page load:
- Windows: In Scan website | Crawler engine select HTTP using WinInet + IE browser
- Windows: In Scan website | Crawler engine select HTTP using Mac OS API + browser
After website scan:
-
For an easy way to see all URLs with
#, use the quick filter. -
If you use
#!for AJAX URLs, you can benefit from:- Enable visibility of data column Core data | URL content state flags detected.
- You can filter or search for flags "[ajaxbyfragmentmeta]" and "[ajaxbyfragmenturl]"
Windows, Mac and Linux
TechSEO360 is available as native software for Windows and Mac.
The Windows installer automatically selects the best binary available depending on the Windows version used, e.g. 32 bit versus 64 bit.
On Linux, you can often instead use virtualization and emulation solutions such as WINE.
The Windows installer automatically selects the best binary available depending on the Windows version used, e.g. 32 bit versus 64 bit.
On Linux, you can often instead use virtualization and emulation solutions such as WINE.
