|
|

TechSEO360-vejledning om websteds- og SEO-revisioner
At analysere din egen hjemmeside er ofte den første ting at gøre i enhver SEO-revision. Her er en trin-for-trin guide.
Bemærk: Vi har en video tutorial:

Oversigt over TechSEO360
Vores software kommer med et bredt arsenal af værktøjer, og denne artikel vil vise, hvordan du bruger de fleste af disse til forskellige website- og SEO-revisionsopgaver.
Du kan springe videre direkte til bestemte dele af denne artikel:
Du kan springe videre direkte til bestemte dele af denne artikel:
- Kom godt i gang - Scan webstedet
- Hurtige rapporter
- Styring af synlige datakolonner
- Opdag interne tilknytningsfejl
- Se linjenumre, ankertekster og Følg/Nofollow for alle links
- Se hvilke billeder der henvises til uden "alt"-tekst
- Forstå vigtigheden af intern navigation og link
- Se alle omdirigeringer, Canonical, NoIndex og lignende
- Tjek for duplicate content
- Optimer sider for bedre SEO inklusive titelstørrelser
- Tilpasset søgewebsted for tekst og kode
- Se de vigtigste søgeord i alt webstedsindhold
- Generer og administrer søgeordslister
- Stavekontrol af hele websteder
- Valider HTML og CSS på alle sider
- Integration med onlineværktøjer
- Gennemgå websteder ved hjælp af et brugerdefineret brugeragent-id og proxy
- Importer liste over URL'er og logfiler til yderligere analyse
- Eksporter data til HTML, CSV og værktøjer som Excel
- Sådan opretter du sitemaps
- Se URL'er med AJAX-fragmenter og indhold
- Windows, Mac og Linux
Kom godt i gang - Scan webstedet
Den første skærm, du ser, er, hvor du kan indtaste hjemmesidens adresse og starte gennemgangen:
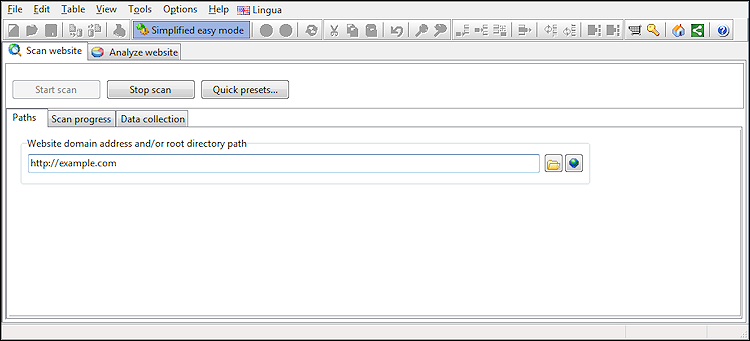
Som standard er de fleste avancerede indstillinger skjult, og softwaren vil bruge sine standardindstillinger.
Men hvis du vil ændre indstillingerne, fx for at indsamle flere data eller øge gennemgangshastigheden ved at øge antallet af maks. forbindelser, kan du gøre alle mulighederne synlige ved at slå Forenklet nem tilstand fra.
På skærmbilledet nedenfor har vi skruet op for arbejdstråde og samtidige forbindelser til max:
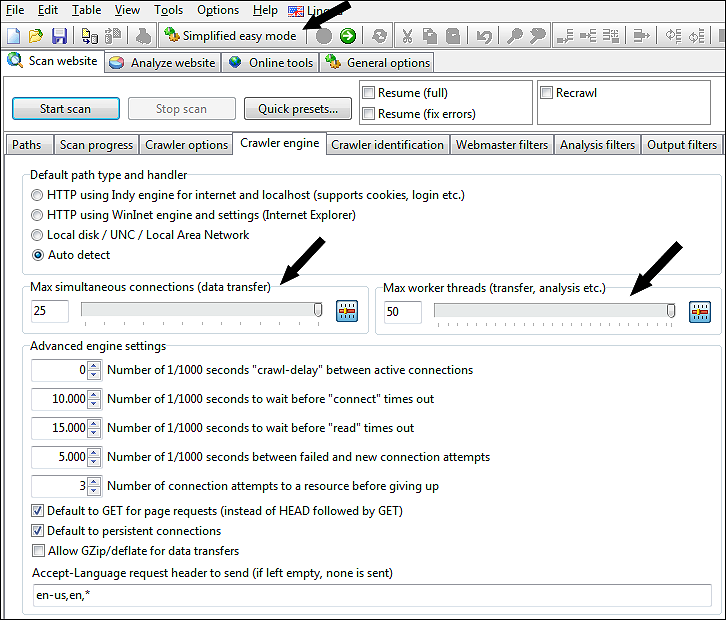
Som standard er de fleste avancerede indstillinger skjult, og softwaren vil bruge sine standardindstillinger.
Men hvis du vil ændre indstillingerne, fx for at indsamle flere data eller øge gennemgangshastigheden ved at øge antallet af maks. forbindelser, kan du gøre alle mulighederne synlige ved at slå Forenklet nem tilstand fra.
På skærmbilledet nedenfor har vi skruet op for arbejdstråde og samtidige forbindelser til max:
Hurtige rapporter
Denne dropdown viser en liste over foruddefinerede "hurtige rapporter", der kan bruges efter scanning af en hjemmeside.
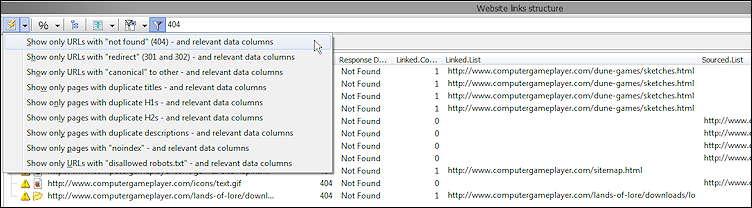
Disse foruddefinerede rapporter konfigurerer følgende muligheder:
Du kan også indstille alle disse manuelt for at oprette dine egne tilpassede rapporter. Denne vejledning indeholder forskellige eksempler på dette, mens du læser den igennem.
Disse foruddefinerede rapporter konfigurerer følgende muligheder:
- Hvilke datakolonner er synlige
- Hvilke "hurtige filtermuligheder" er aktive.
- Den "hurtige filtertekst".
- Aktiverer hurtig filtrering.
Du kan også indstille alle disse manuelt for at oprette dine egne tilpassede rapporter. Denne vejledning indeholder forskellige eksempler på dette, mens du læser den igennem.
Styring af synlige datakolonner
Før vi foretager yderligere analyse efter-scanning af hjemmesiden, skal vi vide, hvordan man tænder og slukker for datakolonner, da det kan være lidt overvældende at se dem alle på én gang.
Billedet nedenfor viser, hvor du kan skjule og vise kolonner.
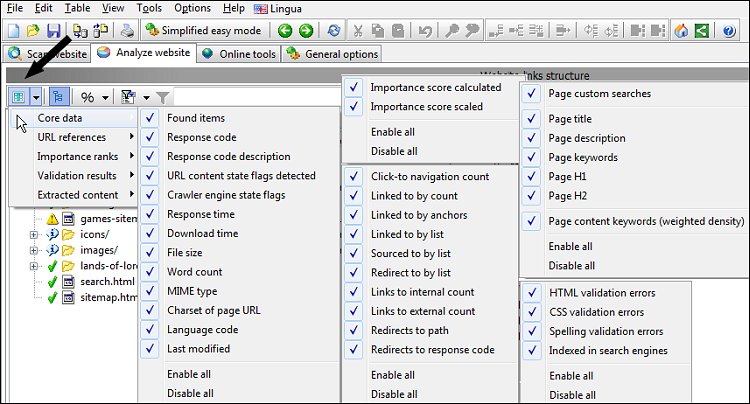
Du vil måske også aktivere eller deaktivere følgende muligheder:
Billedet nedenfor viser, hvor du kan skjule og vise kolonner.
Du vil måske også aktivere eller deaktivere følgende muligheder:
- Se | Tillad store URL-lister i datakolonner
- Se | Tillad relative stier inde i URL-lister i datakolonner
- Se | Vis kun side-URL'er i URL-lister i datakolonner
Opdag interne tilknytningsfejl
Når du tjekker for fejl på en ny hjemmeside, kan det ofte være hurtigst at bruge hurtige filtre. I vores følgende eksempel bruger vi muligheden Vis kun webadresser med filtertekst fundet i "svarkode"-kolonner kombineret med "404" som filtertekst og klik på filtreringsikonet.
Ved at gøre ovenstående får vi en liste over URL'er med svarkode 404 som vist her:
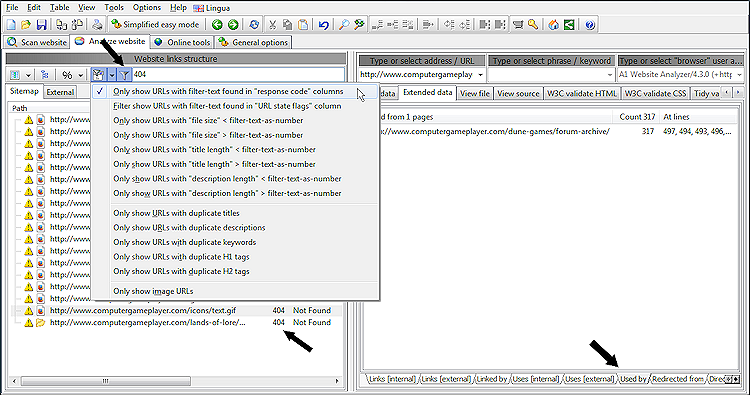
Hvis du vælger en 404 URL i venstre side, kan du til højre se detaljer om, hvordan og hvor den blev opdaget. Du kan se alle URL'er, der linkede, brugte (normalt src- attributten i HTML-tags) eller omdirigeret til 404-URL'en.
Bemærk: For også at få eksterne links markeret, skal du aktivere disse muligheder:
Hvis du vil bruge dette til eksport (forklaret senere nedenfor), kan du også aktivere kolonner, der viser dig de vigtigste interne backlinks og ankertekster.
Ved at gøre ovenstående får vi en liste over URL'er med svarkode 404 som vist her:
Hvis du vælger en 404 URL i venstre side, kan du til højre se detaljer om, hvordan og hvor den blev opdaget. Du kan se alle URL'er, der linkede, brugte (normalt src- attributten i HTML-tags) eller omdirigeret til 404-URL'en.
Bemærk: For også at få eksterne links markeret, skal du aktivere disse muligheder:
- Scan hjemmeside | Dataindsamling | Mulighed for gemte eksterne links
- Scan hjemmeside | Dataindsamling | Bekræft, at eksterne webadresser findes (og analyser, hvis det er relevant)
Hvis du vil bruge dette til eksport (forklaret senere nedenfor), kan du også aktivere kolonner, der viser dig de vigtigste interne backlinks og ankertekster.
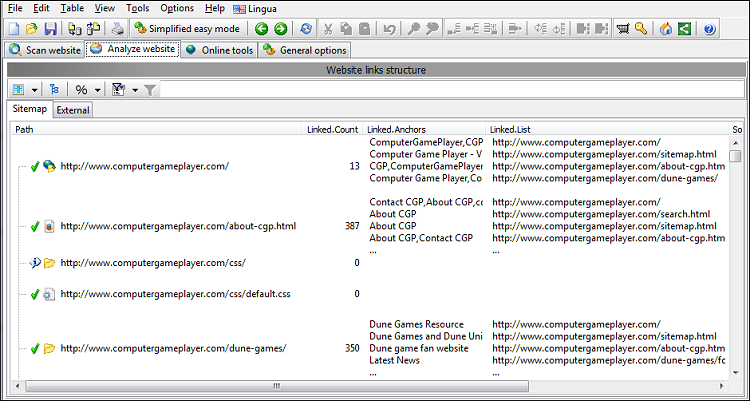
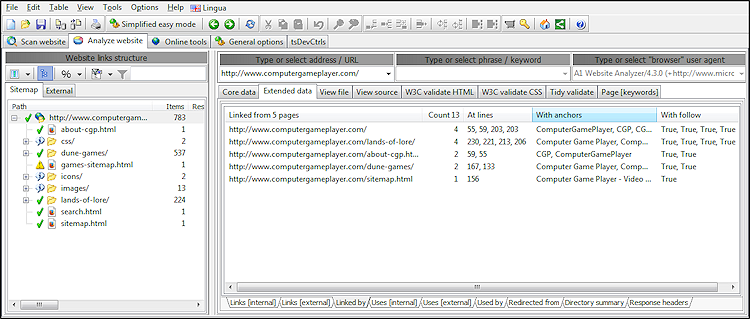
Se linjenumre, ankertekster og Følg/Nofollow for alle links
For alle links fundet på den scannede hjemmeside er det muligt at se følgende information:
For at sikre, at nofollow-links er inkluderet under webcrawling, skal du fjerne markeringen af følgende muligheder i Scan website | Webmaster filtre :
- Linjenummeret i sidekilden, hvor linket findes.
- Ankerteksten knyttet til linket.
- Hvis linket er follow eller nofollow
For at sikre, at nofollow-links er inkluderet under webcrawling, skal du fjerne markeringen af følgende muligheder i Scan website | Webmaster filtre :
- Adlyd metatag "robots" nofollow
- Adlyd et tag "rel" nofollow
Se hvilke billeder der henvises til uden "alt"-tekst
Når du bruger billeder på hjemmesider, er det ofte en fordel at bruge markup, der beskriver dem, altså bruge
Til dette kan du bruge den indbyggede rapport kaldet Vis kun billeder, hvor nogle "linked-by" eller "used-by" savner ankre / "alt". Denne rapport viser alle billeder, der er:
Det opnås ved at:
Når du ser resultater, kan du i udvidede detaljer se, hvor der refereres til hvert billede uden en af ovennævnte teksttyper. På skærmbilledet nedenfor inspicerer vi de brugte data, der stammer fra kilder som
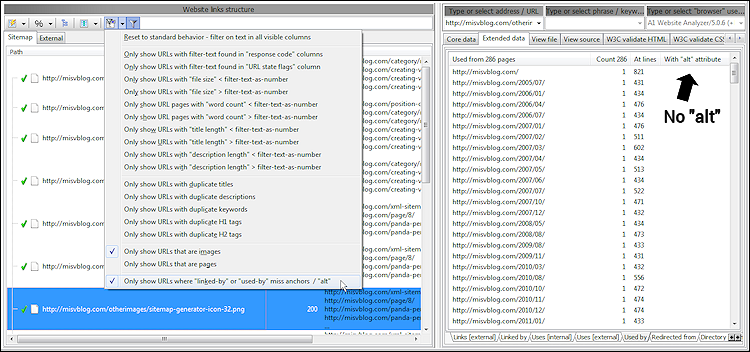
alt attributten i <img> HTML-tagget.Til dette kan du bruge den indbyggede rapport kaldet Vis kun billeder, hvor nogle "linked-by" eller "used-by" savner ankre / "alt". Denne rapport viser alle billeder, der er:
- Brugt uden alternativ tekst
- Linket uden ankertekst.
Det opnås ved at:
- Viser kun relevante datakolonner.
- Aktiver filter: Vis kun webadresser, der er billeder.
- Aktiver filter: Vis kun webadresser, hvor "linked-by" eller "used-by" mangler ankre eller "alt".
Når du ser resultater, kan du i udvidede detaljer se, hvor der refereres til hvert billede uden en af ovennævnte teksttyper. På skærmbilledet nedenfor inspicerer vi de brugte data, der stammer fra kilder som
<img src="example.png" alt="example">. Forstå vigtigheden af intern navigation og link
At forstå, hvordan dit interne websteds struktur hjælper søgemaskiner og mennesker med at finde dit indhold, kan være meget nyttigt.
For at se, hvor mange klik det tager for et menneske at nå en bestemt side fra forsiden, skal du bruge datakolonnens klik til at navigere.
Mens PageRank-skulpturering for det meste er en dag fra fortiden, hjælper dine interne links og linkjuice, der sendes rundt, stadig søgemaskinerne til at forstå, hvilket indhold og hvilke sider du synes er det vigtigste på dit websted.
Vores software beregner automatisk vigtighedsscore for alle URL'er ved hjælp af disse trin:

Du kan påvirke algoritmen gennem menuindstillingerne:
For at inkludere nofollow- links (som vægtes væsentligt lavere end følg- links), skal du fjerne markeringen af disse muligheder på Scan hjemmeside | Webmaster filtre :
Mennesker
For at se, hvor mange klik det tager for et menneske at nå en bestemt side fra forsiden, skal du bruge datakolonnens klik til at navigere.
Søgemaskiner
Mens PageRank-skulpturering for det meste er en dag fra fortiden, hjælper dine interne links og linkjuice, der sendes rundt, stadig søgemaskinerne til at forstå, hvilket indhold og hvilke sider du synes er det vigtigste på dit websted.
Vores software beregner automatisk vigtighedsscore for alle URL'er ved hjælp af disse trin:
- Der tillægges mere vægt på links fundet på sider med mange indgående links.
- Linkjuice en side kan videregive vil blive delt blandt dens udgående links.
- Resultaterne konverteres til en logaritmisk base og skaleres til 0...10.
Du kan påvirke algoritmen gennem menuindstillingerne:
- Værktøjer | Mulighed for vigtighedsalgoritme: Links "reducer" : Vægter gentagne links på samme side mindre og mindre. Vægter links placeret længere nede i indhold mindre og mindre.
- Værktøjer | Mulighed for vigtighedsalgoritme: Links "noself" : Ignorer links, der går til samme side som linket er placeret på.
For at inkludere nofollow- links (som vægtes væsentligt lavere end følg- links), skal du fjerne markeringen af disse muligheder på Scan hjemmeside | Webmaster filtre :
- Adlyd metatag "robots" nofollow
- Adlyd et tag "rel" nofollow
Se alle omdirigeringer, Canonical, NoIndex og lignende
Det er muligt at se oplysninger på hele webstedet om, hvilke URL'er og sider, der er:
Ovenstående data hentes hovedsageligt fra metatags, HTTP-headere og programanalyse af URL'er.
For at se alle data skal du afslutte scanningen af webstedet og aktivere synligheden af disse kolonner:
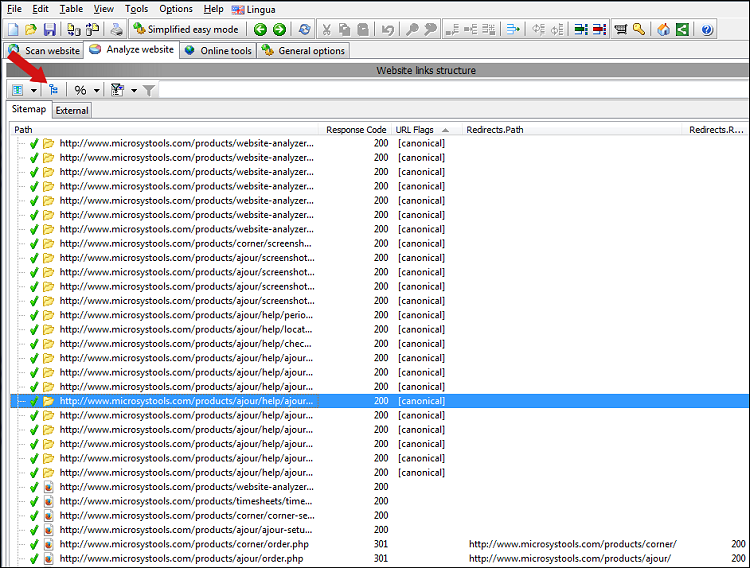
Bemærk, at vi i ovenstående skærmbillede har slået trævisning fra og i stedet ser alle URL'er i listevisningstilstand.
Sådan opsætter du et omfattende filter, der viser alle sider, der omdirigerer på nogen måde:
Dette konfigurerer filtrene, så URL'er kun vises, hvis de matcher følgende betingelser:
- HTTP-omdirigeringer.
- Meta opdatering omdirigeringer.
- Udelukket af robots.txt.
- Markeret kanonisk peger på sig selv, kanonisk peger på en anden URL end sig selv, noindex eller nofollow, noarchive, nosnippet.
- Dubletter af en slags, f.eks. indeks eller manglende skråstreg side-URL'er.
- Og mere..
Ovenstående data hentes hovedsageligt fra metatags, HTTP-headere og programanalyse af URL'er.
For at se alle data skal du afslutte scanningen af webstedet og aktivere synligheden af disse kolonner:
- Kernedata | Sti
- Kernedata | Svarkode
- Kernedata | Flag for URL-indholdstilstand fundet
- URL-referencer | Omdirigeringer tæller
- URL-referencer | Omdirigerer til stien
- URL-referencer | Omdirigerer til svarkode
- URL-referencer | Omdirigerer til sti (endelig)
- URL-referencer | Omdirigerer til svarkode (endelig)
(Dette er især nyttigt for at sikre, at dine omdirigeringsdestinationer er konfigureret korrekt.)
Bemærk, at vi i ovenstående skærmbillede har slået trævisning fra og i stedet ser alle URL'er i listevisningstilstand.
Sådan opsætter du et omfattende filter, der viser alle sider, der omdirigerer på nogen måde:
- Aktiver først muligheder:
- Se | Indstillinger for datafilter | Vis kun webadresser med alle [filter-tekst] fundet i kolonnen "URL-tilstandsflag".
- Se | Indstillinger for datafilter | Vis kun webadresser med et filtertekstnummer, der findes i kolonnen "svarkode".
- Se | Indstillinger for datafilter | Vis kun webadresser, der er sider
- Brug derefter følgende som hurtig filtertekst:
[httpredirect|canonicalredirect|metarefreshredirect] -[noindex] 200 301 302 307
Dette konfigurerer filtrene, så URL'er kun vises, hvis de matcher følgende betingelser:
- URL'en skal være en side - kan fx ikke være et billede.
- URL'en skal enten HTTP-omdirigering eller meta-opdatering eller kanonisk pege til en anden side.
- URL'en må ikke indeholde en noindex-instruktion.
- URL HTTP-svarkoden skal enten være 200, 301, 302 eller 307.
Tjek for duplicate content
Dublerede sidetitler, overskrifter osv.
Det er generelt en dårlig idé at have flere sider til at dele den samme titel, overskrifter og beskrivelser. For at finde sådanne sider kan du bruge den hurtige filterfunktion, efter den første gennemgang af webstedet er afsluttet.
På skærmbilledet nedenfor har vi begrænset vores hurtige filter til kun at vise sider med duplikerede titler, der også indeholder strengen "spillet" i en af dets datakolonner.
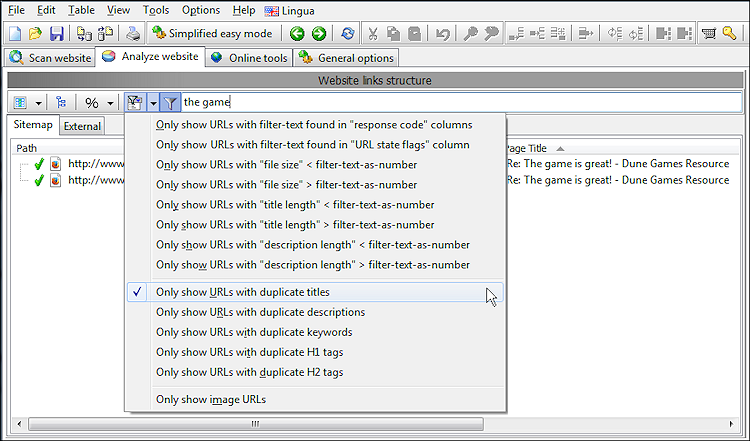
Dubleret sideindhold
Nogle værktøjer kan udføre et simpelt MD5-hash- tjek af alle sider på et websted. Det vil dog kun fortælle dig om sider, der er 100% ens, hvilket ikke er meget sandsynligt, at det sker på de fleste websteder.
I stedet kan TechSEO360 sortere og og gruppere sider med lignende indhold. Derudover kan du se en visuel repræsentation af de mest fremtrædende sideelementer. Tilsammen udgør dette en nyttig kombination til at finde sider, der kan have duplikeret indhold. For at bruge dette:
- Aktiver indstillingen Scan websted | Dataindsamling | Udfør søgeordstæthedsanalyse af alle sider, før du scanner hjemmesiden.
- Aktiver synlighed af datakolonnen Sideindholdslighed.

Før du starter en webstedsscanning, kan du øge nøjagtigheden ved at indstille følgende muligheder i Analyser websted | Søgeordsanalyse.
- Indstil Vælg stopord til at matche hovedsproget på dit websted, eller vælg auto, hvis det bruger flere sprog.
- Indstil Stop ordbrug til Fjernet fra indhold.
- Indstil webstedsanalyse | Max ord i sætning til 2.
- Indstil webstedsanalyse | Max resultater pr. optællingstype til en højere værdi end standardværdien, f.eks. 40.
Bemærk: Hvis du bruger flere sprog på dit websted, skal du læse dette om, hvordan registrering af sidesprog fungerer i TechSEO360.
Dublerede URL'er
Mange websteder indeholder sider, der kan tilgås fra flere unikke URL'er. Sådanne URL'er bør omdirigere eller på anden måde pege søgemaskiner til den primære kilde. Hvis du aktiverer synlighed af datakolonnen Crawler-flag, kan du se alle sidewebadresser, der:
- Eksplicit omdirigere eller pege på andre URL'er ved hjælp af kanonisk, HTTP-omdirigering eller meta-opdatering.
- Er magen til andre URL'er, f.eks. example/dir/, example/dir og example/dir/index.html. For disse beregnes og vises de primære og duplikerede URL'er baseret på HTTP-svarkoder og interne links.
Optimer sider for bedre SEO inklusive titelstørrelser
For dem, der ønsker at lave on-side SEO på alle sider, er der en indbygget rapport, som viser dig de vigtigste datakolonner, herunder:
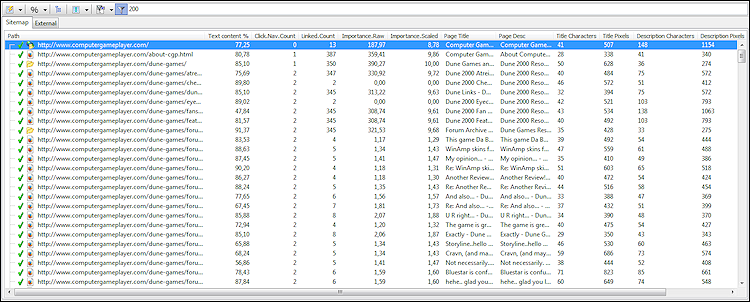
Bemærk: Det er muligt at filtrere dataene på forskellige måder - fx så du kun ser sider, hvor titlerne er for lange til at blive vist i søgeresultaterne.
- Ordantal i sideindhold.
- Tekst versus kodeprocent.
- Titel og beskrivelses længde i tegn.
- Titel og beskrivelses længde i pixels.
- Interne links og sidescore.
- Klik på links, der kræves for at nå en side fra domænets rod.
Bemærk: Det er muligt at filtrere dataene på forskellige måder - fx så du kun ser sider, hvor titlerne er for lange til at blive vist i søgeresultaterne.
Tilpasset søgewebsted for tekst og kode
Før du starter den indledende scanning af webstedet, kan du konfigurere forskellige tekst-/kodemønstre, du vil søge efter, når siderne analyseres og crawles.
Du kan konfigurere dette på Scan hjemmeside | Dataindsamling, og det er muligt at bruge både foruddefinerede mønstre og lave dine egne. Dette kan være meget nyttigt for at se om fx Google Analytics er installeret korrekt på alle sider.
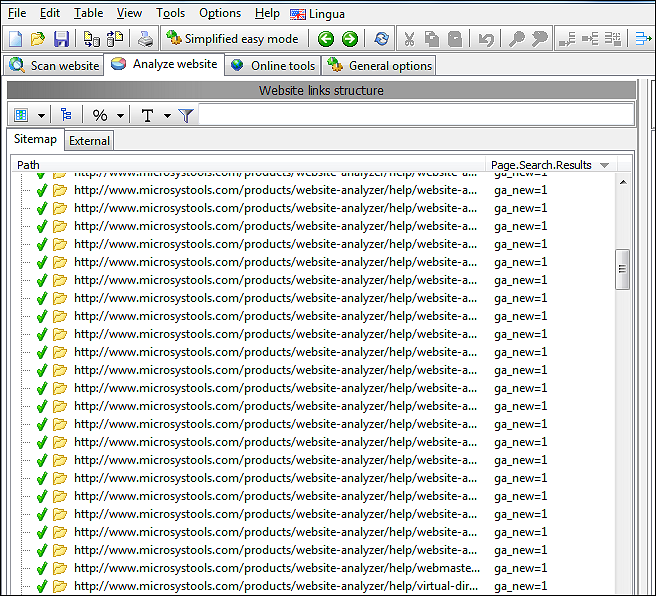
Bemærk, at vi skal navngive hver vores søgemønstre, så vi senere kan skelne mellem dem.
I vores skærmbillede har vi et mønster kaldet ga_new, der søger efter Google Analytic ved hjælp af et regulært udtryk. (Hvis du ikke kender regulære udtryk, vil det ofte også fungere at skrive et uddrag af den tekst eller kode, du vil finde.)
Når du tilføjer og fjerner mønstre, skal du sørge for, at du har tilføjet/fjernet dem fra rullelisten ved hjælp af knapperne [+] og [-].
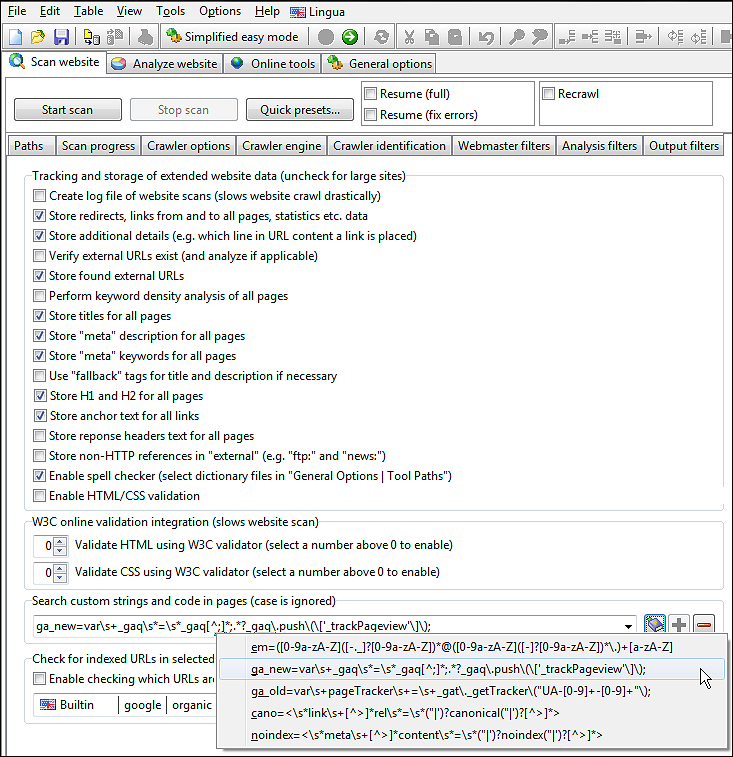
Efter scanningen af hjemmesiden er afsluttet, vil du kunne se, hvor mange gange hvert tilføjet søgemønster blev fundet på alle sider.
Du kan konfigurere dette på Scan hjemmeside | Dataindsamling, og det er muligt at bruge både foruddefinerede mønstre og lave dine egne. Dette kan være meget nyttigt for at se om fx Google Analytics er installeret korrekt på alle sider.
Bemærk, at vi skal navngive hver vores søgemønstre, så vi senere kan skelne mellem dem.
I vores skærmbillede har vi et mønster kaldet ga_new, der søger efter Google Analytic ved hjælp af et regulært udtryk. (Hvis du ikke kender regulære udtryk, vil det ofte også fungere at skrive et uddrag af den tekst eller kode, du vil finde.)
Når du tilføjer og fjerner mønstre, skal du sørge for, at du har tilføjet/fjernet dem fra rullelisten ved hjælp af knapperne [+] og [-].
Efter scanningen af hjemmesiden er afsluttet, vil du kunne se, hvor mange gange hvert tilføjet søgemønster blev fundet på alle sider.
Se de vigtigste søgeord i alt webstedsindhold
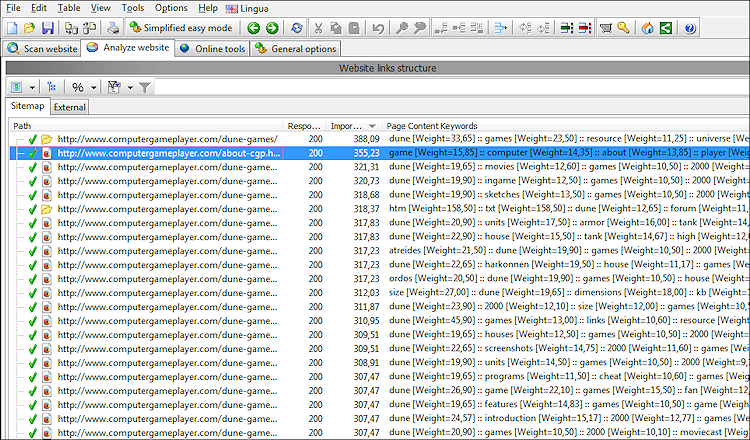
Det er muligt at udtrække de øverste ord på alle sider under webstedscrawl.
For at gøre det skal du markere indstillingen Scan websted | Dataindsamling | Udfør søgeordstæthedsanalyse af alle sider.
Algoritmen, der beregner søgeordsscore, tager følgende ting i betragtning:
De scoringer, du ser, er formateret på en måde, der er læsbar for mennesker, men som også er let at lave yderligere analyser på ved hjælp af brugerdefinerede scripts og værktøjer. (Hvilket er nyttigt, hvis du vil eksportere dataene.)
Hvis du hellere vil have en detaljeret opdeling af søgeord på enkelte sider, kan du også få det:

Det er også her, du kan konfigurere, hvordan søgeordsscore beregnes. Hvis du vil vide mere om dette, kan du se hjælpesiden til A1 Keyword Research om analyse af søgeord på siden .
For at gøre det skal du markere indstillingen Scan websted | Dataindsamling | Udfør søgeordstæthedsanalyse af alle sider.
Algoritmen, der beregner søgeordsscore, tager følgende ting i betragtning:
- Forsøger at registrere sprog og anvende den korrekte liste over stopord.
- Søgeordstætheden i den komplette sidetekst.
- Tekst inde i vigtige HTML-elementer har større betydning end normal tekst.
De scoringer, du ser, er formateret på en måde, der er læsbar for mennesker, men som også er let at lave yderligere analyser på ved hjælp af brugerdefinerede scripts og værktøjer. (Hvilket er nyttigt, hvis du vil eksportere dataene.)
Hvis du hellere vil have en detaljeret opdeling af søgeord på enkelte sider, kan du også få det:
Det er også her, du kan konfigurere, hvordan søgeordsscore beregnes. Hvis du vil vide mere om dette, kan du se hjælpesiden til A1 Keyword Research om analyse af søgeord på siden .
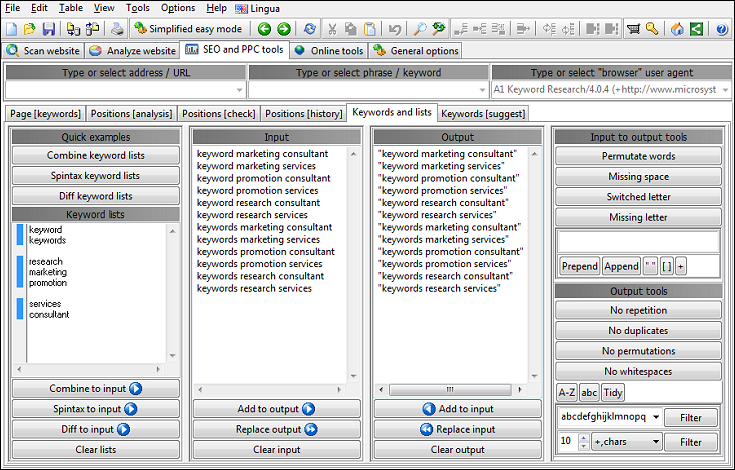
Generer og administrer søgeordslister
Hvis du nogensinde har brug for at oprette eller vedligeholde søgeordslister, kommer TechSEO360 indbygget med kraftfulde søgeordsværktøjer, du kan bruge til at generere, kombinere og rense søgeordslister.
Stavekontrol af hele websteder
Hvis du i Scan hjemmeside | Dataindsamling vælger at lave stavekontrol, du kan også se antallet af stavefejl for alle sider efter gennemgangen er afsluttet.
For at se de specifikke fejl, kan du se kildekoden for den efterfølgende ved at klikke på Værktøjer | Stavekontroldokument.

Som det ses, kan ordbogsfilerne i ikke indeholde alt, så du vil ofte have gavn af at lave en foreløbig scanning, hvor du tilføjer almindelige ord, der er specifikke for din hjemmesides niche, til ordbogen.

For at se de specifikke fejl, kan du se kildekoden for den efterfølgende ved at klikke på Værktøjer | Stavekontroldokument.
Som det ses, kan ordbogsfilerne i ikke indeholde alt, så du vil ofte have gavn af at lave en foreløbig scanning, hvor du tilføjer almindelige ord, der er specifikke for din hjemmesides niche, til ordbogen.
Valider HTML og CSS på alle sider
TechSEO360 kan bruge flere forskellige HTML/CSS-sidetjek, herunder W3C/HTML, W3C/CSS, Tidy/HTML, CSE/HTML og CSE/CSS.
Da HTML/CSS-validering kan gøre webstedsgennemgang langsommere, er disse muligheder som standard ikke markeret.
Liste over muligheder brugt til HTML/CSS-validering:
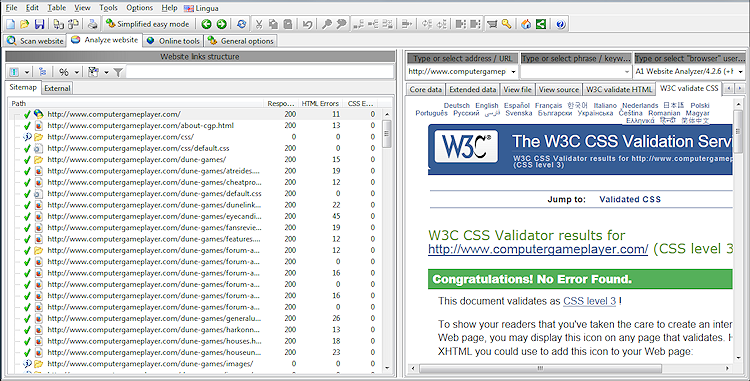
Når du er færdig med en hjemmesidescanning med HTML/CSS-validering aktiveret, vil resultatet se sådan ud:
Da HTML/CSS-validering kan gøre webstedsgennemgang langsommere, er disse muligheder som standard ikke markeret.
Liste over muligheder brugt til HTML/CSS-validering:
- Scan hjemmeside | Dataindsamling | Aktiver HTML/CSS-validering
- Generelle muligheder og værktøjer | Værktøjsstier | TIDY eksekverbar sti
- Generelle muligheder og værktøjer | Værktøjsstier | CSE HTML Validator kommandolinje eksekverbar sti
- Scan hjemmeside | Dataindsamling | Valider HTML ved hjælp af W3C HTML Validator
- Scan hjemmeside | Dataindsamling | Valider CSS ved hjælp af W3C CSS Validator
Når du er færdig med en hjemmesidescanning med HTML/CSS-validering aktiveret, vil resultatet se sådan ud:
Integration med onlineværktøjer
For at lette det daglige arbejdsflow har softwaren en separat fane med forskellige 3. parts onlineværktøjer.
Afhængigt af den valgte URL og tilgængelige data, kan du vælge et af onlineværktøjerne i rullelisten, og den korrekte URL inklusive forespørgselsparametre åbnes automatisk i en integreret browser.
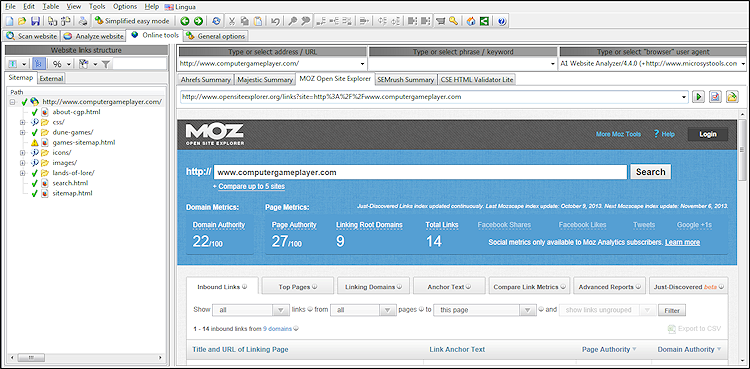
Afhængigt af den valgte URL og tilgængelige data, kan du vælge et af onlineværktøjerne i rullelisten, og den korrekte URL inklusive forespørgselsparametre åbnes automatisk i en integreret browser.
Gennemgå websteder ved hjælp af et brugerdefineret brugeragent-id og proxy
Nogle gange kan det være nyttigt at skjule brugeragent-id og IP-adresse, der bruges ved gennemgang af websteder.
Mulige årsager kan være, hvis et websted:
Du kan konfigurere disse ting i Generelle muligheder og værktøjer | Internet crawler.
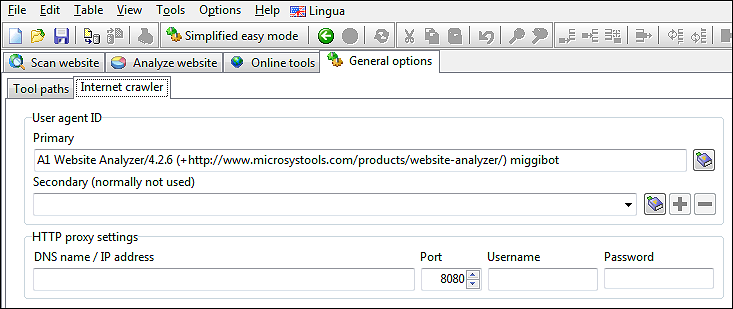
Mulige årsager kan være, hvis et websted:
- Returnerer andet indhold for crawlere end mennesker, dvs. website-cloaking.
- Bruger IP-adresseintervaller til at registrere land efterfulgt af omdirigering til en anden side/websted.
Du kan konfigurere disse ting i Generelle muligheder og værktøjer | Internet crawler.
Importer data fra tredjepartstjenester
Du kan importere URL'er og udvidede data fra 3. parter gennem menuen Filer | Importer URL'er fra tekst/log/csv.
Afhængigt af hvad du importerer, vil alle URL'erne blive placeret i enten de interne eller eksterne faner.
Importering kan bruges til både at tilføje flere oplysninger til eksisterende crawldata og til at se nye crawls.
Der importeres yderligere data, når kildedataene stammer fra:
For at starte en webstedscrawl fra de importerede URL'er kan du:
For at gennemgå de importerede webadresser på den eksterne fane, skal du markere muligheder:
Afhængigt af hvad du importerer, vil alle URL'erne blive placeret i enten de interne eller eksterne faner.
Importering kan bruges til både at tilføje flere oplysninger til eksisterende crawldata og til at se nye crawls.
Der importeres yderligere data, når kildedataene stammer fra:
- Apache- serverlogfiler:
- Hvilke sider er blevet tilgået af GoogleBot. Dette vises af [googlebot] i datakolonnen URL-flag.
- Hvilke URL'er, der ikke er internt linket eller brugt. Dette vises af [forældreløs] i datakolonnen URL-flag.
- Google Search Console CSV-eksporter:
- Hvilke sider er indekseret af Google. Dette vises af [googleindexed] i datakolonnen URL-flag.
- Klik på hver webadresse i Googles søgeresultater - dette vises i datakolonnen Klik.
- Visninger af hver webadresse i Googles søgeresultater - dette vises i datakolonnen Visninger.
- Majestætisk CSV-eksport:
- Link-score for alle URL'er - dette vises i datakolonnen Backlinks-score. Når de er tilgængelige, bruges dataene til yderligere at forbedre beregningerne bag datakolonnerne Vigtighedsscore beregnet og Vigtighedsscore skaleret.
For at starte en webstedscrawl fra de importerede URL'er kan du:
- Afkryds mulighed Scan websted | Gencrawl.
- Afkryds mulighed Scan websted | Gencrawl (kun angivet) - dette vil undgå at inkludere nye URL'er til analysekø og resultatoutput.
For at gennemgå de importerede webadresser på den eksterne fane, skal du markere muligheder:
- Scan hjemmeside | Dataindsamling | Mulighed for gemte eksterne links
- Scan hjemmeside | Dataindsamling | Bekræft, at eksterne webadresser findes (og analyser, hvis det er relevant)
Eksporter data til HTML, CSV og værktøjer som Excel
Generelt kan du eksportere indholdet af enhver datakontrol ved at fokusere/klikke på den efterfulgt af fil | Eksporter valgte data til fil... eller Fil | Eksporter valgte data til udklipsholder... menupunkter.
Standarden er at eksportere data som standard .CSV-filer, men hvis det program, du har til hensigt at importere .CSV-filerne til, har specifikke behov, eller hvis du gerne vil have f.eks. kolonneoverskrifter opført også, kan du justere indstillingerne i menu Filer | Eksporter og importer muligheder.
De data, du normalt eksporterer, findes i hovedvisningen. Her kan du oprette tilpassede eksporter og rapporter, der indeholder netop de oplysninger, du har brug for. Vælg blot hvilke kolonner der er synlige, aktivér de hurtige filtre du ønsker (f.eks. kun 404 ikke fundet fejl, duplikerede titler eller lignende) før eksport.
Alternativt kan du også bruge de indbyggede rapporteringsknapper, der indeholder forskellige konfigurationsforudindstillinger:
Bemærk: Du kan oprette mange flere datavisninger, hvis du lærer, hvordan du konfigurerer filtre og synlige kolonner.
Standarden er at eksportere data som standard .CSV-filer, men hvis det program, du har til hensigt at importere .CSV-filerne til, har specifikke behov, eller hvis du gerne vil have f.eks. kolonneoverskrifter opført også, kan du justere indstillingerne i menu Filer | Eksporter og importer muligheder.
De data, du normalt eksporterer, findes i hovedvisningen. Her kan du oprette tilpassede eksporter og rapporter, der indeholder netop de oplysninger, du har brug for. Vælg blot hvilke kolonner der er synlige, aktivér de hurtige filtre du ønsker (f.eks. kun 404 ikke fundet fejl, duplikerede titler eller lignende) før eksport.
Alternativt kan du også bruge de indbyggede rapporteringsknapper, der indeholder forskellige konfigurationsforudindstillinger:
Bemærk: Du kan oprette mange flere datavisninger, hvis du lærer, hvordan du konfigurerer filtre og synlige kolonner.
Sådan opretter du sitemaps
Brug knappen Hurtige forudindstillinger... til at optimere din crawl - f.eks. for at oprette et video-sitemap til et websted med eksternt hostede videoer.
Bagefter skal du blot klikke på knappen Start scanning for at starte en hjemmesidegennemgang.

Når webstedsscanningen er færdig, skal du vælge den type sitemap-fil, du vil oprette, og klikke på knappen Byg valgt.
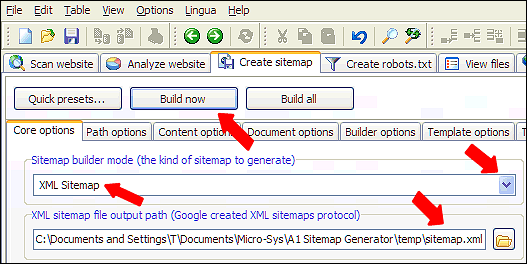
Du kan finde en komplet liste over selvstudier for hver type sitemap-fil i vores onlinehjælp.
Bagefter skal du blot klikke på knappen Start scanning for at starte en hjemmesidegennemgang.
Når webstedsscanningen er færdig, skal du vælge den type sitemap-fil, du vil oprette, og klikke på knappen Byg valgt.
Du kan finde en komplet liste over selvstudier for hver type sitemap-fil i vores onlinehjælp.
Se URL'er med AJAX-fragmenter og indhold
Hurtig forklaring af fragmenter i URL'er:
Før webstedsscanning:
Efter scanning af hjemmesiden:

- Page-relative-fragments : Relative links på en side:
http://example.com/somepage#relative-page-link - AJAX-fragmenter : Javascript på klientsiden, der forespørger kode på serversiden og erstatter indholdet i browseren:
http://example.com/somepage#lookup-replace-data
http://example.com/somepage#!lookup-replace-data - AJAX-fragments-Google-initiative : En del af Google- initiativet gør AJAX-applikationer crawlbare :
http://example.com/somepage#!lookup-replace-data
Denne løsning er siden blevet fordømt af Google selv.
Før webstedsscanning:
- Hash- fragmenter
#fjernes ved brug af standardindstillinger. For at ændre dette, fjern markeringen:- In Scan hjemmeside | Crawler-indstillinger | Udskæring "#" i interne links
- In Scan hjemmeside | Crawler-indstillinger | Udskæring "#" i eksterne links
- Hashbang- fragmenter
#!er altid opbevaret og inkluderet. - Hvis du vil analysere AJAX-indhold hentet umiddelbart efter den første sideindlæsning:
- Windows : In Scan hjemmeside | Crawler-motoren vælger HTTP ved hjælp af WinInet + IE browser
- Windows : In Scan hjemmeside | Crawler-motoren vælger HTTP ved hjælp af Mac OS API + browser
Efter scanning af hjemmesiden:
- For en nem måde at se alle URL'er med
#, brug hurtigfilteret. - Hvis du bruger
#!for AJAX URL'er kan du drage fordel af:- Aktiver synlighed af datakolonnen Kernedata | URL-indholdstilstandsflag fundet.
- Du kan filtrere eller søge efter flag "[ajaxbyfragmentmeta]" og "[ajaxbyfragmenturl]"
Windows, Mac og Linux
TechSEO360 er tilgængelig som indbygget software til Windows og Mac.
Windows-installationsprogrammet vælger automatisk den bedst tilgængelige binære version afhængigt af den anvendte Windows-version, f.eks. 32 bit versus 64 bit.
På Linux kan man ofte i stedet bruge virtualiserings- og emuleringsløsninger såsom WINE.
Windows-installationsprogrammet vælger automatisk den bedst tilgængelige binære version afhængigt af den anvendte Windows-version, f.eks. 32 bit versus 64 bit.
På Linux kan man ofte i stedet bruge virtualiserings- og emuleringsløsninger såsom WINE.
