|
|

Scrape Website Data into CSV, XML, SQL and Databases
How to configure A1 Website Scraper program for scraping data off websites into CSV files, XML files and SQL databases
Note: We have a video tutorial:
Scrape and Extract Data Options
In the initial screen with website scraping and data extraction options you can:
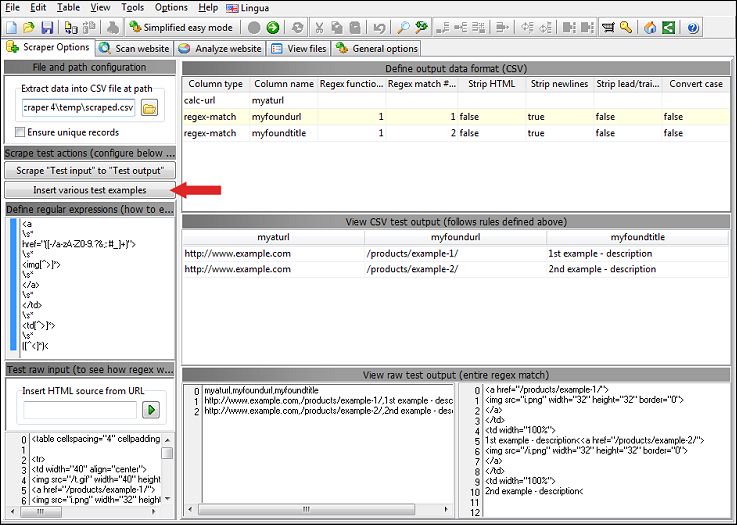
- Configure options:
- Regular expressions used for extracting data from crawled pages.
- Control how extracted data is formatted and converted into CSV data.
- Test options:
- Insert test input page content
- View formatted output data (CSV)
- View raw output data
- Various scrape preset tests that prefills all of above mentioned.
- Various buttons that make it easier to create and test settings including regular expressions used for extraction.
Different Website Scrape Demo Presets
To the bottom right you can find a section call
Insert various text examples. Under this you can find buttons that
will pre-fill all options with a a test/demo example including:
- Page content that gets data scraped.
- Regular expressions and XPath instructions that extract the data.
- Configuration of how the extracted data gets formatted into CSV, XML and SQL files.
- How the output looks like.
Regular Expressions and Data Output Configuration
-
Section: Define regular expressions
-
When you define a regular expression, each pair of
()is considered a match. Match IDs start at#1. A Match contains the data matched and extracted by the given regular expression into the given()match. -
You can define multiple regular expressions by inserting an empty line between them.
Regular expression IDs start at
#1.
-
When you define a regular expression, each pair of
-
Section: Define output data format
- When configuring how the CSV file output is formatted, you can configure how each column is generated in the output CSV file. For far most columns, you will column type to be regex-match.
- You can control how the column data is filled and formatted including which regular expression regex function #ID and which regex match #ID () is used as data source.
Regular Expressions Help and Tricks
While regular expressions can often be daunting, here is a few tricks you can use together with the demo examples:
By combining above regex constructs (which are common to all regular expression implementations) together with HTML code snippets from the pages you want to scrape, you can extract data into CSV files from most websites.
Note: A1 Website Scraper will trim each line in your regular expressions for whitespaces to make formatting easier. Be sure to use \s to represent whitespaces.
For more information, you can check the following resources:
.+will match any character in content one or more times..*will match any character in content zero or more times. (This is rarely useful, see alternative below.).*?will match any character in content until the following regex code can match the content.\s*will match all whitespaces in content zero or more times. (So if any spaces are found, they are all matched.)\s+will match all whitespaces in content one or more times. (Meaning a minimum of one space has to be matched.)\swill match one whitespace in content one time. (Meaning only a single space will be matched.)[0-9a-zA-Z]will match an English letter or digit in content one time.[^<]*will match any character except "<" in content zero or more times.()will make the regex code inside the parentheses store the matched content in a match #ID. (See above section for explanation.)(this|that|the)will match "this" or "that" or "the" + store the matched content in a match #ID.(this|that|the)?will do like above if a match is possible, but will continue with the following regex under all circumstances.
By combining above regex constructs (which are common to all regular expression implementations) together with HTML code snippets from the pages you want to scrape, you can extract data into CSV files from most websites.
Note: A1 Website Scraper will trim each line in your regular expressions for whitespaces to make formatting easier. Be sure to use \s to represent whitespaces.
For more information, you can check the following resources:
- Book: Regular Expressions in 10 Minutes by Ben Forta (quick to read)
- Book: Mastering Regular Expressions by Jeffrey E. F Friedl
Scrape an Entire Website
The steps required to scrape an entire website:
- First define and test your scrape configuration in Scraper options.
- If the website uses AJAX for delayed content loading, be sure to configure Scan website | Crawler engine for it.
- Make sure you select a valid CSV file output path in Scraper options for Extract data into CSV file path.
- In Scan website | Paths enter the domain address to crawl and scrape data from.
- In Scan website click the Start scan button to begin the process.
- After the scan has finished, A1 Website Scraper will generate a .csv file at the selected path that contains the data scraped.
- If the file was created successfully, the content of it will automatically be shown in the View files tab.
Filter Which URLs in a Single Website to Scrape
If you need to scrape data from a simple website:
If you need to extract data from a complex website:

It is important to note that URLs you scrape data from have to pass filters defined in both analysis filters and output filters.
- Enter the root address of where the data is located.
- Click the Start scan to initiate the website crawl.
If you need to extract data from a complex website:
- Enter the root address of where the data is located.
- Disable easy mode.
- Configure analysis filters to control which URLs get content analyzed for links etc.
- Configure output filters to control which URLs you scrape data from.
- Start scan.
It is important to note that URLs you scrape data from have to pass filters defined in both analysis filters and output filters.
Scrape List of URLs from Multiple Websites
- Create a file with a list of URLs and import them.
(If the list contains URLs from different domains, they are automatically placed in External tab in Analyze website | Website analysis section.) - Tick the Scan website | Recrawl option.
- Tick the Scan website | Data collection | Verify external URLs exist option.
CSV File Character Encoding and Other Options
You can configure the encoding and character format of the generated CSV file:
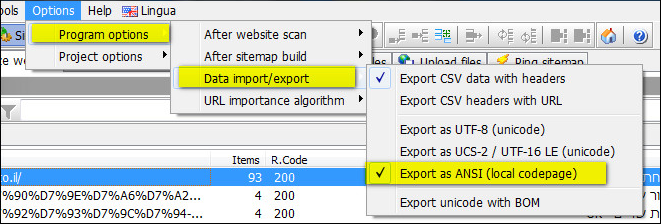
Depending on the tool/database you wish to import the CSV file to, you may need to configure the above before website scan.
- UTF-8 with optional BOM. (ASCII is a subset of UTF-8. Ideal for English documents.)
- UTF-16 LE (UCS-2) with optional BOM. (Used internally in current Windows systems.)
- Local ANSI codepage. (May not always be portable to other platforms and languages.)
Depending on the tool/database you wish to import the CSV file to, you may need to configure the above before website scan.
