|
|

Scrapen Sie Website-Daten in CSV, XML, SQL und Datenbanken
So konfigurieren Sie das A1 Website Scraper-Programm zum Scrapen von Daten von Websites in CSV-Dateien, XML-Dateien und SQL-Datenbanken
Hinweis: Wir haben ein Video-Tutorial:
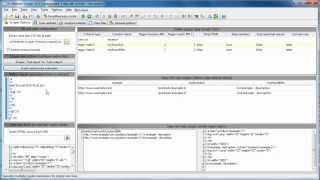
Optionen zum Scrapen und Extrahieren von Daten
Im Startbildschirm mit Website-Scraping- und Datenextraktionsoptionen können Sie:

- Optionen konfigurieren:
- Reguläre Ausdrücke, die zum Extrahieren von Daten aus gecrawlten Seiten verwendet werden.
- Steuern Sie, wie extrahierte Daten formatiert und in CSV-Daten konvertiert werden.
- Testmöglichkeiten:
- Fügen Sie den Inhalt der Testeingabeseite ein
- Formatierte Ausgabedaten anzeigen (CSV)
- Rohe Ausgabedaten anzeigen
- Verschiedene voreingestellte Scrape-Tests, die alle oben genannten Punkte vorab ausfüllen.
- Verschiedene Schaltflächen, die das Erstellen und Testen von Einstellungen einschließlich der zur Extraktion verwendeten regulären Ausdrücke erleichtern.
Verschiedene Website-Scrape-Demo-Voreinstellungen
Unten rechts finden Sie einen Abschnitt mit dem Aufruf Verschiedene Textbeispiele einfügen. Darunter finden Sie Schaltflächen, die alle Optionen mit einem Test-/Demobeispiel vorab ausfüllen, einschließlich:
- Seiteninhalt, bei dem Daten gescrapt werden.
- Reguläre Ausdrücke und XPath-Anweisungen, die die Daten extrahieren.
- Konfiguration, wie die extrahierten Daten in CSV-, XML- und SQL-Dateien formatiert werden.
- Wie die Ausgabe aussieht.
Reguläre Ausdrücke und Datenausgabekonfiguration
- Abschnitt: Reguläre Ausdrücke definieren
- Wenn Sie einen regulären Ausdruck definieren, wird jedes Paar von
()als Übereinstimmung betrachtet. Match-IDs beginnen bei#1. Ein Match enthält die Daten, die durch den angegebenen regulären Ausdruck abgeglichen und in die angegebene()-Übereinstimmung extrahiert wurden. - Sie können mehrere reguläre Ausdrücke definieren, indem Sie eine Leerzeile dazwischen einfügen. IDs für reguläre Ausdrücke beginnen bei
#1.
- Wenn Sie einen regulären Ausdruck definieren, wird jedes Paar von
- Abschnitt: Ausgabedatenformat definieren
- Beim Konfigurieren der Formatierung der CSV-Dateiausgabe können Sie konfigurieren, wie jede Spalte in der CSV-Ausgabedatei generiert wird. Für die meisten Spalten wählen Sie den Spaltentyp „regex-match“ aus.
- Sie können steuern, wie die Spaltendaten gefüllt und formatiert werden, einschließlich der Regex-Funktion #ID für reguläre Ausdrücke und der Regex-Übereinstimmung #ID (), die als Datenquelle verwendet werden.
Hilfe und Tricks zu regulären Ausdrücken
Während reguläre Ausdrücke oft entmutigend sein können, finden Sie hier ein paar Tricks, die Sie zusammen mit den Demo-Beispielen anwenden können:
Durch die Kombination der oben genannten Regex-Konstrukte (die allen regulären Ausdrucksimplementierungen gemeinsam sind) mit HTML-Codeausschnitten von den Seiten, die Sie durchsuchen möchten, können Sie Daten von den meisten Websites in CSV-Dateien extrahieren.
Hinweis: A1 Website Scraper schneidet jede Zeile in Ihren regulären Ausdrücken ab, um Leerzeichen zu entfernen, um die Formatierung zu erleichtern. Stellen Sie sicher, dass Sie zur Darstellung von Leerzeichen \s verwenden.
Weitere Informationen finden Sie in den folgenden Ressourcen:
-
.+stimmt mit jedem Zeichen im Inhalt einmal oder mehrmals überein. -
.*stimmt mit jedem Zeichen im Inhalt null oder mehrmals überein. (Dies ist selten nützlich, siehe Alternative unten.) -
.*?stimmt mit jedem Zeichen im Inhalt überein , bis der folgende Regex- Code mit dem Inhalt übereinstimmen kann. -
\s*stimmt mit allen Leerzeichen im Inhalt null oder mehrmals überein. (Wenn also Leerzeichen gefunden werden, werden sie alle abgeglichen.) -
\s+gleicht alle Leerzeichen im Inhalt einmal oder mehrmals ab. (Das bedeutet, dass mindestens ein Leerzeichen übereinstimmen muss.) -
\sentspricht einmal einem Leerzeichen im Inhalt. (Das bedeutet, dass nur ein einzelnes Leerzeichen gefunden wird.) -
[0-9a-zA-Z]entspricht einmal einem englischen Buchstaben oder einer englischen Ziffer im Inhalt. -
[^<]*stimmt mit jedem Zeichen außer „<“ im Inhalt null oder mehrmals überein. -
()bewirkt, dass der Regex-Code in den Klammern den übereinstimmenden Inhalt in einer Übereinstimmungs-#ID speichert. (Erklärung finden Sie im Abschnitt oben.) -
(this|that|the)stimmt mit „this“ oder „that“ oder „the“ überein + speichert den übereinstimmenden Inhalt in einer Match-#ID. -
(this|that|the)?wird wie oben verfahren , wenn eine Übereinstimmung möglich ist, wird aber unter allen Umständen mit dem folgenden regulären Ausdruck fortfahren.
Durch die Kombination der oben genannten Regex-Konstrukte (die allen regulären Ausdrucksimplementierungen gemeinsam sind) mit HTML-Codeausschnitten von den Seiten, die Sie durchsuchen möchten, können Sie Daten von den meisten Websites in CSV-Dateien extrahieren.
Hinweis: A1 Website Scraper schneidet jede Zeile in Ihren regulären Ausdrücken ab, um Leerzeichen zu entfernen, um die Formatierung zu erleichtern. Stellen Sie sicher, dass Sie zur Darstellung von Leerzeichen \s verwenden.
Weitere Informationen finden Sie in den folgenden Ressourcen:
- Buch: Reguläre Ausdrücke in 10 Minuten von Ben Forta (schnell zu lesen)
- Buch: Mastering Regular Expressions von Jeffrey E. F Friedl
Scrapen Sie eine gesamte Website
Die erforderlichen Schritte zum Scrapen einer gesamten Website:
- Definieren und testen Sie zunächst Ihre Scrape- Konfiguration in den Scraper-Optionen.
- Wenn die Website AJAX zum verzögerten Laden von Inhalten verwendet, müssen Sie Website scannen | konfigurieren Raupenmotor dafür.
- Stellen Sie sicher, dass Sie in den Scraper-Optionen für „Daten in CSV-Dateipfad extrahieren“ einen gültigen CSV-Dateiausgabepfad auswählen.
- In Website scannen | Pfade geben die Domänenadresse ein, aus der Daten gecrawlt und extrahiert werden sollen.
- Klicken Sie auf der Scan-Website auf die Schaltfläche „Scan starten“, um den Vorgang zu starten.
- Nachdem der Scan abgeschlossen ist, generiert A1 Website Scraper im ausgewählten Pfad eine CSV- Datei, die die gescrapten Daten enthält.
- Wenn die Datei erfolgreich erstellt wurde, wird der Inhalt automatisch auf der Registerkarte „Dateien anzeigen“ angezeigt.
Filtern Sie, welche URLs auf einer einzelnen Website gescrapt werden sollen
Wenn Sie Daten von einer einfachen Website extrahieren müssen:
Wenn Sie Daten von einer komplexen Website extrahieren müssen:
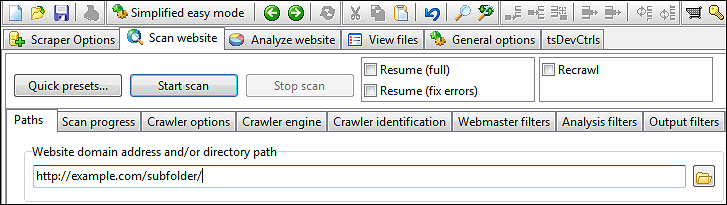
Es ist wichtig zu beachten, dass URLs, von denen Sie Daten extrahieren, Filter passieren müssen, die sowohl in Analysefiltern als auch in Ausgabefiltern definiert sind.
- Geben Sie die Stammadresse ein, an der sich die Daten befinden.
- Klicken Sie auf „Scan starten“, um den Website-Crawling zu starten.
Wenn Sie Daten von einer komplexen Website extrahieren müssen:
- Geben Sie die Stammadresse ein, an der sich die Daten befinden.
- Deaktivieren Sie den einfachen Modus.
- Konfigurieren Sie Analysefilter, um zu steuern, welche URLs Inhalte auf Links usw. analysieren lassen.
- Konfigurieren Sie Ausgabefilter, um zu steuern, von welchen URLs Sie Daten extrahieren.
- Scan starten.
Es ist wichtig zu beachten, dass URLs, von denen Sie Daten extrahieren, Filter passieren müssen, die sowohl in Analysefiltern als auch in Ausgabefiltern definiert sind.
Scrapen Sie eine Liste von URLs von mehreren Websites
- Erstellen Sie eine Datei mit einer Liste von URLs und importieren Sie diese.
(Wenn die Liste URLs von verschiedenen Domänen enthält, werden diese automatisch auf der Registerkarte „Extern“ im Abschnitt „Website analysieren | Website-Analyse“ platziert.) - Markieren Sie Website scannen | Recrawl- Option.
- Markieren Sie Website scannen | Datenerfassung | Option „Existieren externer URLs überprüfen“.
Zeichenkodierung für CSV-Dateien und andere Optionen
Sie können die Kodierung und das Zeichenformat der generierten CSV-Datei konfigurieren:

Abhängig von dem Tool/der Datenbank, in die Sie die CSV-Datei importieren möchten, müssen Sie möglicherweise vor dem Website-Scan die oben genannten Einstellungen vornehmen.
- UTF-8 mit optionaler Stückliste. (ASCII ist eine Teilmenge von UTF-8. Ideal für englische Dokumente.)
- UTF-16 LE (UCS-2) mit optionaler Stückliste. (Wird in aktuellen Windows-Systemen intern verwendet.)
- Lokale ANSI-Codepage. (Möglicherweise nicht immer auf andere Plattformen und Sprachen portierbar.)
Abhängig von dem Tool/der Datenbank, in die Sie die CSV-Datei importieren möchten, müssen Sie möglicherweise vor dem Website-Scan die oben genannten Einstellungen vornehmen.
