|
|

Sitemapper håndterer webstedsplatforme og -problemer
Website-crawleren i A1 Sitemap Generator er ligeglad med den platform, dine hjemmesider bruger, om det er PHP eller ASP, om det er dynamisk eller statisk, til mobil eller ej osv.
Din hjemmesidetype og server betyder ikke noget
URL-omskrivning og lignende
Din hjemmeside kan uden problemer bruge virtuelle mapper eller URL-omskrivning. Mange mennesker bruger Apache mod_rewrite til at oprette virtuelle mapper og URL'er. Lignende løsninger findes for næsten alle webserverløsninger.
Fra et crawlerperspektiv kan websteder sikkert bruge virtuelle mapper og URL'er. Browsere, søgemaskinebots osv. ser alle din hjemmeside udefra. De har ingen viden om, hvordan din URL-struktur er implementeret. De kan ikke se, om sider eller mapper er fysiske eller virtuelle.
Serversidesprog og HTML-websider
På en moderne hjemmeside er der ofte ringe eller ingen sammenhæng mellem URL'en "filnavne" og de underliggende data, herunder hvordan det genereres, gemmes og hentes. Det er lige meget, om en hjemmeside bruger Cold Fusion, ASP.Net, JSP, PHP eller lignende som programmeringssprog på serversiden. Webstedscrawlere ser kun koden på klientsiden (HTML/CSS/Javascript) genereret af koden og databaserne på serveren.
Bemærk: I indstillinger kan crawleren i vores webstedsanalyseværktøj indstilles til at acceptere/ignorere URL'er med visse filtypenavne og MIME-indholdstyper. Hvis du har problemer, så læs om at finde alle sider og links.
Dynamisk skabt indhold på server
Websteder, der dynamisk genererer sideindhold ved hjælp af scripts og databaser på serversiden, crawles uden problemer af webstedscrawlere og robotter.
Bemærk: Nogle søgemaskinerobotter kan blive langsommere, når de crawler webadresser med ?. Det er dog hovedsageligt, fordi søgemaskinerne er bekymrede for at bruge ressourcer på at crawle på masser af webadresser med automatisk genereret indhold. For at afbøde dette kan du bruge mod rewrite eller lignende på din hjemmeside.
Bemærk: Vores sitemap-generator og MiggiBot-crawler-motoren er ligeglade med, hvordan URL'er ser ud.
Mobile hjemmesider
Mange hjemmesider bruger i dag responsive og adaptive layouts, der justerer sig selv i browseren ved hjælp af klient-side teknologier, f.eks. CSS og Javascript.
Nogle websteder har dog særlige websteds-URL'er for:
- Funktionstelefoner, der kun understøtter WAP og lignende gamle teknologier.
- Smartphones med browsere, der minder meget om desktopbrowsere og gengiver indhold på samme måde.
- Stationære computere, bærbare computere og tablets, hvor skærmområdet og visningsporten er større.
Generelt ved sådanne mobiloptimerede websteder, at de skal outputte indhold, der er optimeret til mobilenheder ved enten:
- Antag, at de altid skal udsende indhold, der er optimeret til et givet sæt mobile enheder, f.eks. smartphones.
- Udfør kontrol på serversiden af den brugeragent, der er sendt til den af crawleren eller browseren. Hvis en mobilenhed derefter identificeres, vil den enten omdirigere til en ny URL eller blot udsende indhold, der er optimeret til mobile enheder.
Hvis du ønsker, at A1 Sitemap Generator-crawleren skal se det mobile indhold og de URL'er, dit websted udsender til mobile enheder, skal du blot ændre indstillingen Generelle muligheder og værktøjer | Internet-crawler | Brugeragent-id til en, der bruges af populære mobile enheder, f.eks. dette:
Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, ligesom Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19.
Du kan gøre det samme med de fleste desktop-browsere ved at installere et brugeragent switcher plugin. Det giver dig mulighed for at inspicere koden, der returneres af dit websted til mobilbrowsere.
Bemærk: Hvis dit mobiloptimerede websted bruger en blanding af klientside- og serversideteknologier såsom AJAX til at detektere brugeragenten og ændre indhold baseret på den, vil det ikke fungere på mange webstedscrawlere, herunder fra og med september 2014 i det mindste , A1 Sitemap Generator. Det vil dog fungere i de fleste browsere, da de kører/udfører Javascript- kode, som kan forespørge browseren om brugeragent-id'et.
AJAX hjemmesider
Hvis din hjemmeside bruger AJAX, som er en teknologi, hvor Javascript kommunikerer med serveren og ændrer indholdet i browseren uden at ændre URL-adresse, er det værd at vide, at crawlbarhed vil afhænge af den nøjagtige implementering.
Forklaring af fragmenter i URL'er:
- Page-relative-fragments : Relative links på en side:
http://example.com/somepage#relative-page-link - AJAX-fragmenter : Javascript på klientsiden, der forespørger kode på serversiden og erstatter indholdet i browseren:
http://example.com/somepage#lookup-replace-data - AJAX-fragments-Google-initiative : En del af Google-initiativet gør AJAX-applikationer crawlbare :
http://example.com/somepage#!lookup-replace-data
Denne løsning er siden blevet fordømt af Google selv. For mere information se:
https://developers.google.com/webmasters/ajax-crawling/docs/getting-started
https://developers.google.com/webmasters/ajax-crawling/docs/specification
Hvis du bruger denne løsning, vil du se URL'er indeholdende#!og_escaped_fragment_ved gennemgang.
Bemærk: Det er værd at bemærke, at kun URL'er med gyldigt indhold vil blive inkluderet i de genererede XML-sitemaps.
Tip: Sådan hjælper du med at crawle AJAX-websteder:
- Vælg en AJAX-aktiveret crawlerindstilling på Scan websted | Crawler motor.
- Aktiver indstillingen Scan websted | Crawler muligheder | Prøv at søge i Javascript.
- Aktiver indstillingen Scan websted | Crawler muligheder | Prøv at søge i JSON.
Bekræft hjemmesidens HTML-output til crawlere og browsere
Normalt skjuler websteder aldrig indhold baseret på brugeragentstreng og IP-adresse. Ved at indstille brugeragent-id'et kan du dog kontrollere den HTML-kilde, søgemaskiner og browsere ser, når de henter sider fra dit websted.
Bemærk: Dette kan også bruges til at teste, om et websted reagerer korrekt på en crawler/browser, der identificerer sig selv som værende mobil.
Bemærk: Dette kan også bruges til at teste, om et websted reagerer korrekt på en crawler/browser, der identificerer sig selv som værende mobil.
Sådan scanner du dit websted med succes og fuldstændigt
Hvis du har problemer med at crawle websteder, bør du læse om svar om at finde alle links og sider i webstedsscanninger.
Du bør også sikre dig, at der ikke er nogen firewall eller internetsikkerhedssoftware, der blokerer A1 Sitemap Generator.
Du bør også sikre dig, at der ikke er nogen firewall eller internetsikkerhedssoftware, der blokerer A1 Sitemap Generator.
Problematiske websteder og specifikke webstedsplatforme
Webstedets båndbreddefiltrering og/eller drosling
Nogle få webstedsplatforme og -moduler træffer foranstaltninger mod crawlere, de ikke genkender, for at reservere båndbredde og serverbrug til rigtige besøgende og søgemaskiner. Her er en liste over kendte løsninger til disse webstedsplatforme:
- Joomla-websteder: Joomla sitemap-generator.
- NetSuite-websteder: NetSuite-sitemapgenerator.
- e107 CMS-websteder: e107 sitemap generator.
- Ebay Store websteder: Ebay sitemap generator.
Hvis du forsøger at crawle et forum, så tjek vores guide til optimal crawl af fora og blogs med sitemapgenerator.
Hjemmesiden sender uregelmæssigt det forkerte sideindhold
Vi har set et par tilfælde, hvor webstedet, serveren, CDN, CMS eller cache-systemet led af en fejl og sendte det forkerte outputsideindhold, da det blev crawlet.
For at bevise og diagnosticere et sådant problem skal du downloade og konfigurere A1-webstedsdownload sådan her:
- Indstil Scan hjemmeside | Download muligheder | Konverter URL-stier i downloadet indhold til ingen konvertering.
- Aktiver Scan websted | Dataindsamling | Gem omdirigeringer og links fra og til alle sider.
- Aktiver alle muligheder i Scan websted | Webmaster filtre.
Du kan nu sammenligne den downloadede sidekildekode med det, der er rapporteret i A1-webstedets download, og se om webserveren/webstedet sendte korrekt eller forkert indhold til A1-crawlermotoren.
For at løse et sådant problem uden adgang til webstedet og webserverkoden, prøv at bruge nogle af de konfigurationer, der er foreslået længere nede nedenfor.
Generelle løsninger til at crawle problematiske websteder
Hvis du støder på et websted, der dæmper crawler-anmodninger, blokerer visse brugeragenter eller er meget langsom, vil du ofte få svarkoder som:
For at løse disse, prøv følgende:
Bemærk: Hvis du fortsat har problemer, kan du kombinere ovenstående med:
Bemærk: Hvis din IP-adresse er blevet blokeret, kan du prøve at bruge Generelle muligheder og værktøjer | Internet-crawler | HTTP-proxyindstillinger. Proxy-support afhænger af, hvilken HTTP-motor der er valgt på Scan-webstedet | Crawler motor.
Bemærk: Hvis problemet er timeout-fejl, kan du også prøve at gentage gennemgange med genoptag-scanningsfunktionen.
Du kan også downloade vores standard projektfil til problematiske websteder, da du ofte kan anvende de samme løsninger på en lang række websteder.
- 403 forbudt
- 503 : Tjenesten midlertidigt utilgængelig
- -5 : TimeoutConnectError
- -6 : TimeoutReadError
For at løse disse, prøv følgende:
- Indstil Scan hjemmeside | Crawler motor | Max samtidige forbindelser til en.
- Sæt Crawler-motor | Avancerede motorindstillinger | Standard for at GET anmodninger skal kontrolleres/aktiveres.
- Lad derefter webcrawleren om nødvendigt identificere sig selv som en søgemaskine eller som en bruger, der surfer.
- Identificer som "bruger-surf-websted":
- Indstil generelle indstillinger og værktøjer | Internet-crawler | Brugeragent-id til Mozilla/4.0 (kompatibel; MSIE 7.0; Win32).
- Indstil Scan hjemmeside | Webmaster filtre | Download "robots.txt" til umarkeret/deaktiveret.
- In Scan hjemmeside | Crawlermotor øger mængden af tid mellem aktive forbindelser.
- Valgfrit: : Indstil Scan websted | Crawler-motor til HTTP ved hjælp af WinInet-motor og indstillinger (Internet Explorer)
- Identificer som "søgemaskinecrawler":
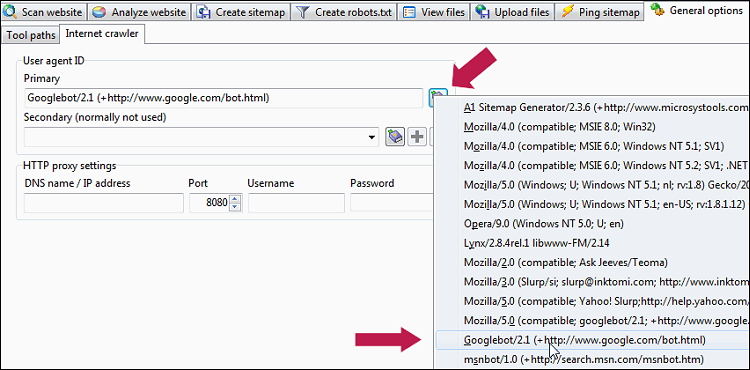
- Indstil generelle indstillinger og værktøjer | Internet-crawler | Brugeragent-id til Googlebot/2.1 (+http://www.google.com/bot.html) eller et andet søgemaskine-crawler-id.
- Indstil Scan hjemmeside | Webmaster filtre | Download "robots.txt" til markeret/aktiveret.
- Indstil Scan hjemmeside | Webmaster filtre | Adlyd "robots.txt"-filen "disallow"-direktivet til markeret/aktiveret.
- Indstil Scan hjemmeside | Webmaster filtre | Adlyd "robots.txt" fil "crawl-delay" direktivet til markeret/aktiveret.
- Indstil Scan hjemmeside | Webmaster filtre | Adlyd "meta"-tag "robots" noindex for at kontrolleres/aktiveres.
- Indstil Scan hjemmeside | Webmaster filtre | Adlyd "meta"-tag "robots" nofollow for at markeret/aktiveret.
- Indstil Scan hjemmeside | Webmaster filtre | Adlyd "a" tag "rel" nofollow til markeret/aktiveret.
- Identificer som "bruger-surf-websted":
Bemærk: Hvis du fortsat har problemer, kan du kombinere ovenstående med:
- Indstil Scan hjemmeside | Crawler motor | Crawl-forsinkelse i millisekunder mellem forbindelser til mindst 3000.
Bemærk: Hvis din IP-adresse er blevet blokeret, kan du prøve at bruge Generelle muligheder og værktøjer | Internet-crawler | HTTP-proxyindstillinger. Proxy-support afhænger af, hvilken HTTP-motor der er valgt på Scan-webstedet | Crawler motor.
Bemærk: Hvis problemet er timeout-fejl, kan du også prøve at gentage gennemgange med genoptag-scanningsfunktionen.
Du kan også downloade vores standard projektfil til problematiske websteder, da du ofte kan anvende de samme løsninger på en lang række websteder.
