|
|

Import and Crawl a List of Pages to Generate Sitemaps
Explains the easiest way to setup the sitemap generator program to crawl and analyze a list of specific pages from a website.
Note: We have a video tutorial:
Even though the video demonstration uses TechSEO360 some of it is also applicable for users of A1 Sitemap Generator.
Even though the video demonstration uses TechSEO360 some of it is also applicable for users of A1 Sitemap Generator.
Import The Page URLs into Sitemap Generator
Before doing anything else, you will first have to import the list of pages you want. You can do so from the File menu.
In the newest versions, the menu item used for importing is titled Import URLs and data from file using "smart" mode...
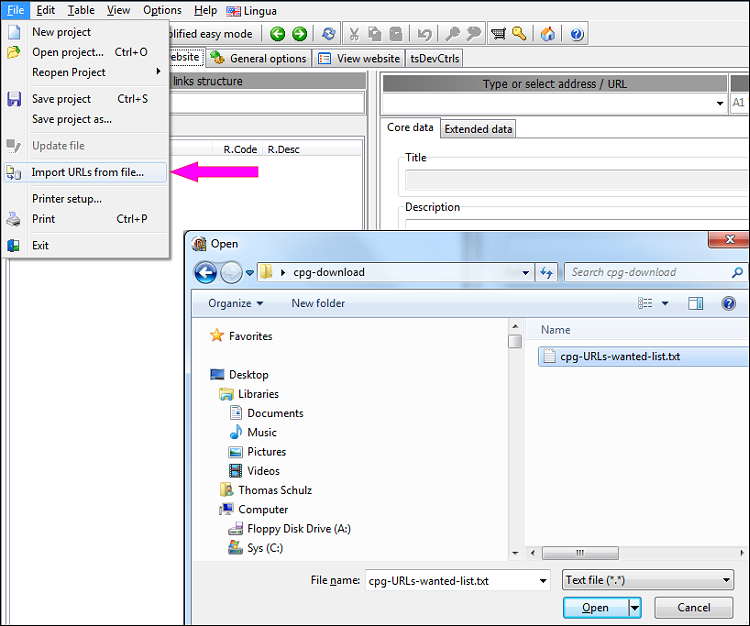
Select a file containing the list of URLs you wish to import. It can be in a variety of formats including .CSV, .SQL and .TXT.
The software will automatically (try to) determine which URLs go into the internal and external tabs.
It will do so by recognizing if the majority of the imported URLs are:
Note: If you already have existing website data loaded, A1 Sitemap Generator will add the imported URLs if the root domain is the same.
Note: To force all imported URLs into the external category tab, you can use File | Import URLs and data from file into "external" list...
In the newest versions, the menu item used for importing is titled Import URLs and data from file using "smart" mode...
Select a file containing the list of URLs you wish to import. It can be in a variety of formats including .CSV, .SQL and .TXT.
The software will automatically (try to) determine which URLs go into the internal and external tabs.
It will do so by recognizing if the majority of the imported URLs are:
- From the same domain and place those in the internal category tab. (The rest will be ignored.)
- From multiple domains and place those in the external category tab. (The rest will be ignored.)
Note: If you already have existing website data loaded, A1 Sitemap Generator will add the imported URLs if the root domain is the same.
Note: To force all imported URLs into the external category tab, you can use File | Import URLs and data from file into "external" list...
Crawl Imported Internal URLs
Crawling imported URLs belonging to a single website is straightforward.
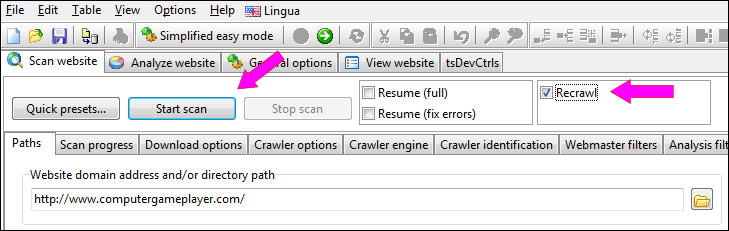
Before starting the scan after import, select one of the recrawl options:
You can now click the Start scan button.
Before starting the scan after import, select one of the recrawl options:
- Scan website | Recrawl (full) - this will crawl new URLs found during scan.
- Scan website | Recrawl (listed only) - this will avoid including any new URLs for analysis or scan results.
You can now click the Start scan button.
Limit The Crawl of Internal URLs
Note: This section is only necessary if you want to further limit the crawl of internal URLs.
You can skip this step if either:
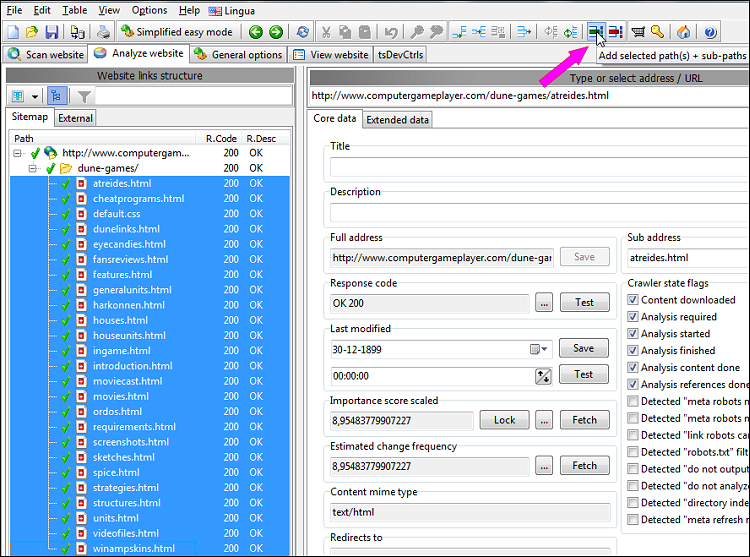
An easy way to limit the crawl of internal URLs is to use the button shown in the picture below.
This will add all selected website URLs to a limit include to list in both analysis filters and output filters.
Note: if you want to limit which URLs to include in recrawls, it is often easier to switch the left view to list mode.
Note: If you want to have URLs checked that are not in the imported list, you will need to ensure the crawler is allowed to analyze and include them in results.
Note: Remember to keep the following options checked if you use output filters:
That way, only the URLs you are interested in will be shown after the site crawl has finished.
Note: If you forget to use one of the recrawl modes, and you use limit crawl to filters, the scan may be unable to start if you excluded all the URLs used to initiate the site crawl from.
You can skip this step if either:
- The above section Crawl Imported Internal URLs is sufficient for your needs.
- You are only interested in external URLs.
An easy way to limit the crawl of internal URLs is to use the button shown in the picture below.
This will add all selected website URLs to a limit include to list in both analysis filters and output filters.
Note: if you want to limit which URLs to include in recrawls, it is often easier to switch the left view to list mode.
Note: If you want to have URLs checked that are not in the imported list, you will need to ensure the crawler is allowed to analyze and include them in results.
Note: Remember to keep the following options checked if you use output filters:
- Older versions: Scan website | Crawler options | Apply "webmaster" and "ouput" filters after website scan stops
- Newer versions: Scan website | Output filters | After website scan stops: Remove URLs excluded
That way, only the URLs you are interested in will be shown after the site crawl has finished.
Note: If you forget to use one of the recrawl modes, and you use limit crawl to filters, the scan may be unable to start if you excluded all the URLs used to initiate the site crawl from.
Crawl Imported External URLs
-
In case you want to have external URLs checked:
- Untick the Scan website | Crawler Engine | Default to GET for page requests option.
- Tick the Scan website | Data collection | Store found external URLs option.
- Tick the Scan website | Data collection | Verify external URLs (and analyze if applicable) option.
-
In case you want to have external URLs analyzed:
- Tick the Scan website | Crawler Engine | Default to GET for page requests option.
- Tick the Scan website | Data collection | Store found external URLs option.
- Tick the Scan website | Data collection | Verify external URLs (and analyze if applicable) option.
-
As can be seen above, the main difference is the option Default to GET for page requests in Scan website | Crawler engine.
- GET requests work with all servers, but are slower since they download all page content.
- HEAD requests sometimes get blocked, but are usually much faster as they only download HTTP headers.
Start The Crawl and View The Results
-
Hit the start scan button.
-
Wait for the scan to finish.
-
View results.
Note: It is usually easier viewing the results when switching the left view to list mode.
- If you want to export the results, see the help page about exporting data to CSV files.
