|
|

Beim Website-Suchmaschinen-Crawl werden nicht alle URLs gefunden
Was tun, wenn Sie nach dem Website-Crawling durch ein Website-Suchmaschinenprogramm nur wenige Links sehen?
Wenn das Website-Suchmaschinenprogramm zu wenige oder ungerade Seiten-URLs findet
Lesen Sie zunächst, wie die A1-Website-Suchmaschine dabei hilft, Probleme mit der Website-Verlinkung zu finden. Dann gehen Sie diese Checkliste durch:
- Verwenden Sie ein Firewall- Programm? Sie müssen es konfigurieren, wenn der Website-Scan nur wenige URLs zurückgibt und alle den Antwortcode -4: CommError haben.
- Vermischen Sie bei Website-Links und -Weiterleitungen die Verwendung von WWW- und Nicht-WWW- Inhalten? Weitere Informationen finden Sie auf der Registerkarte „Externals“.
- Verwendet Ihre Website Website-Cloaking, d. h. ändert sich der Inhalt abhängig von der vom Crawler verwendeten User-Agent-Zeichenfolge ? Ändern Sie dann die Zeichenfolge des Benutzeragenten, die der Crawler verwendet, um sich selbst zu identifizieren: Allgemeine Optionen und Tools | Internet-Crawler | Benutzeragenten-ID.
- Leitet Ihre Website und/oder die darin enthaltenen Seiten zu einer anderen Domain weiter oder erhält sie Inhalte von dieser? (z. B. über <frame> oder <iframe>) Weitere Informationen finden Sie auf der Registerkarte „Externals“.
- Ist ein ganzer Seitenbereich ausgeblendet und von den anderen Teilen der Website überhaupt nicht verlinkt? In diesem Fall hilft es nicht, alle versteckten Seiten zu verlinken! Um dieses Problem zu lösen, können Sie mehrere Startsuchpfade verwenden.
- Ist die Website auf Javascript oder ungewöhnliche Arten von HTML-Link-Tags für die Website-Navigation angewiesen, z. B. <iframe>, <form> und <button> ? Lösung: Aktivieren Sie die Überprüfung dieser Dinge auf Links unter Website scannen | Crawler-Optionen.
- Verwendet die Website // anstelle von / in Links? Und antwortet der Webserver in solchen Fällen nicht mit einem Fehler oder einer Weiterleitung? Und tritt das Problem auf, wenn die Seiten-URL über relative Pfade verlinkt ist? Lösung: Scan-Website konfigurieren | Crawler-Optionen zur Bewältigung dieser Situation.
- Verfügt die Website über eine dynamische Seite, die anhand der Eingaben von GET eindeutige Links generiert? Daten? Dies kann manchmal zu einer Endlosschleife eindeutiger URLs führen!
- Verschiedene Ausschlussfilter in Programmkonfiguration und Website:
- Blockieren Sie Seiten mit robots.txt- oder noindex- Meta-Tags? Erfahren Sie mehr über nofollow, noindex und robots.txt.
- Haben Sie die Analyse so konfiguriert, dass bestimmte URLs und Ausgabefilter ausgeschlossen werden, und haben diese vergessen?
Denken Sie daran: Wenn Sie einige Seiten-URLs von der Analyse ausschließen, kann der Crawler die Links auf diesen Seiten nicht finden oder ihnen nicht folgen. Wenn Sie URLs haben, die ansonsten nirgendwo verlinkt sind, werden diese URLs nie gefunden oder analysiert.
Sie können auch konfigurieren, wann URLs durch „Website scannen“ ausgeschlossen werden sollen Ausgabefilter, robots.txt und ähnliches werden entfernt:- Ältere Versionen:
- Website scannen | Crawler-Optionen | Wenden Sie die Filter „Webmaster“ und „Ausgabe“ an, nachdem der Website-Scan beendet wurde
- Neuere Versionen:
- Website scannen | Ausgabefilter | Nachdem der Website-Scan beendet wurde: Ausgeschlossene URLs entfernen
- Website scannen | Webmaster-Filter | Nachdem der Website-Scan beendet wurde: URLs mit noindex/disallow entfernen
Wenn Sie das oben genannte deaktivieren, können Sie mögliche Gründe für fehlende URLs leichter finden. Im Abschnitt „Crawler- und URL-Statusflags“ für jede URL können Sie viele Details sehen. Wenn Sie immer noch Probleme haben, herauszufinden, warum eine Seiten-URL fehlt, untersuchen Sie die gesamte Linkkette, indem Sie die Flags für noindex, nofollow, disallow und ähnliches überprüfen. Möglicherweise möchten Sie auch die HTML-Quelle überprüfen, um sicherzustellen, dass die Links korrekt codiert sind.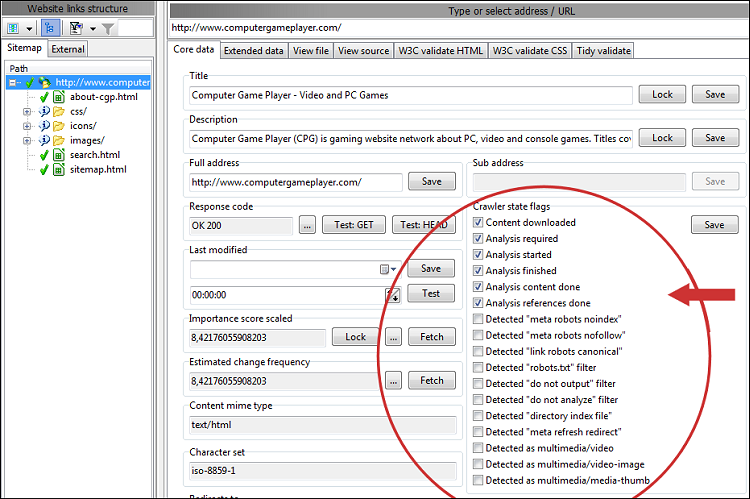
- Scannen Sie ein Website-Unterverzeichnis, das keine Links zu Seiten in diesem Verzeichnis enthält? Weitere Informationen finden Sie auf der Registerkarte „Externals“.
- Überlegen Sie, ob Ihre Website nicht standardmäßige Dateierweiterungen verwendet. Wenn Sie wissen, welche, können Sie sie hinzufügen:

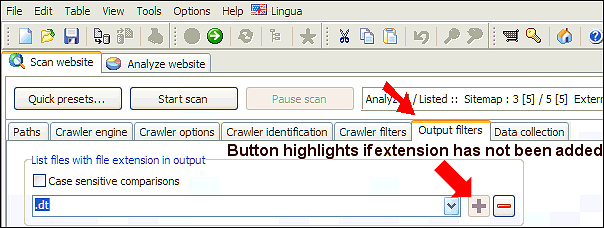
Alternativ können Sie alle Dateierweiterungen in den Analyse- und Ausgabefiltern löschen, aber die Standard- MIME- Filter an beiden Stellen beibehalten. Versuchen Sie dann erneut, den Scanvorgang durchzuführen. - Haben Sie Verzeichnisse mit dem Antwortcode 0: VirtualItem in den Scanergebnissen? Überprüfen Sie die Informationen zur internen Website-Verlinkung.
- Gibt es viele URLs mit Fehlern in den Website-Scan-Ergebnissen? Wenn der Webserver dazu führt, dass einige URLs Fehlerantwortcodes ausgeben, z. B. aufgrund der Drosselung der Serverbandbreite, können Sie versuchen, den Scan fortzusetzen, bis alle Fehler behoben sind. Dies wird höchstwahrscheinlich zu mehr gefundenen Links und Seiten führen.
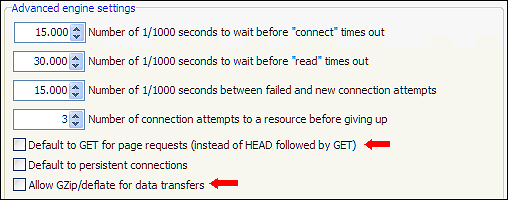
Eine weitere Lösung zur Lösung von URLs mit Fehlerantworten besteht darin, mit den Optionen unter Website scannen | zu experimentieren Raupenmotor | Erweiterte Motoreinstellungen. Einige allgemeine Einstellungen, die oft hilfreich sind: Erhöhen der Timeout- Werte, ausschließliche Verwendung von GET und Aktivieren/Deaktivieren der GZip/defalte- Unterstützung.