|
|

Website-Suchmaschinenanalysefilter im Website-Scan
Mithilfe von Website-Scan-Analysefiltern (auch Crawler-Filter genannt) können Sie festlegen, welche Seiten bei Website-Scans in unserer Website-Suchmaschine auf Inhalte und Links analysiert werden sollen.
Hinweis: Wir haben ein Video-Tutorial:
Obwohl die Videodemonstration TechSEO360 verwendet, ist ein Teil davon auch für Benutzer der A1 Website Search Engine anwendbar.
Obwohl die Videodemonstration TechSEO360 verwendet, ist ein Teil davon auch für Benutzer der A1 Website Search Engine anwendbar.
Übersicht über Website-Analysefilter für Suchmaschinen
Analysefilter bestimmen, welche Seiten ihren Inhalt auf Links und andere Daten analysieren lassen. Sie können stattdessen oder in Verbindung mit Webmaster-Filtern (robots.txt, noindex, nofollow usw.) und Ausgabefiltern Analysefilter verwenden.
- Schließen Sie URLs sowohl in Analysefiltern als auch in Ausgabefiltern aus, um Crawlzeit, HTTP-Anfragen und Speichernutzung zu minimieren.
- Hinweis: Wenn eine URL nur von Seiten verlinkt wird, die aufgrund von Filtern nicht analysiert werden, wird sie beim Website-Scan nicht gefunden.
- Hinweis: Damit Änderungen an den Analysefiltern wirksam werden, müssen Sie Ihre Website erneut crawlen.
Beschränken Sie interne URLs auf diejenigen in diesen Verzeichnissen
- Vom Crawler gefundene Links werden normalerweise in die Kategorien „intern“ und „extern“ gruppiert.
- Mit dieser Option können Sie entscheiden, welche Seiten in die interne Kategorie gehören.
Analysieren Sie Dateien mit Dateierweiterung
URLs mit Dateierweiterungen, die nicht in der Liste gefunden werden, werden beim Website-Scan nicht analysiert.
Wenn Sie alle Dateierweiterungen in der Liste entfernen, akzeptiert die Filterung der Dateierweiterungsliste alle Dateien.

Wenn Sie alle Dateierweiterungen in der Liste entfernen, akzeptiert die Filterung der Dateierweiterungsliste alle Dateien.
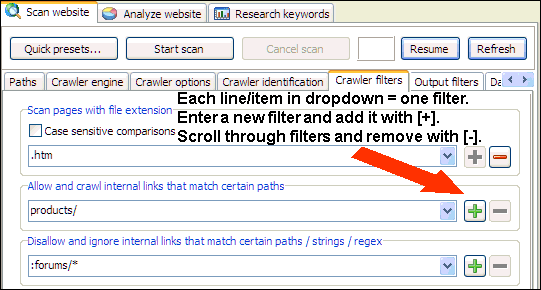
Analysieren Sie keine URLs, die mit Pfaden/Strings/Regex übereinstimmen
Der Ausschluss von URLs, die ganz oder teilweise mit einer Textzeichenfolge, einem Pfad oder einem regulären Ausdrucksmuster übereinstimmen, von der Analyse ist oft eine gute Möglichkeit, das Crawlen einzuschränken.
Aus den obigen Beispielen ist Folgendes ersichtlich:
So fügen Sie ein Listenfilterelement im Dropdown-Menü hinzu: Geben Sie es ein und verwenden Sie die Schaltfläche [+].
So entfernen Sie ein Listenfilterelement im Dropdown: Wählen Sie es aus und verwenden Sie die Schaltfläche [-].
Sie können weitere Informationen zu den verwendeten Benutzeroberflächensteuerelementen anzeigen
- Saiten:
- blogs stimmt mit relativen Pfaden überein, die „ blogs “ enthalten.
- @ stimmt mit relativen Pfaden überein, die „ @ “ enthalten.
- ? Entspricht relativen Pfaden, die „ ? “ enthalten.
- Pfade:
- : s stimmt mit relativen Pfaden überein, die mit „ s “ beginnen, z. B. http://www.microsystools.com/services/ und http://www.microsystools.com/shop/.
- : blogs/ stimmt mit relativen Pfaden überein, die mit „ blogs/ “ beginnen, wie z. B. http://www.microsystools.com/ blogs/.
- Unterpfade:
- : blogs/ * stimmt mit relativen Pfaden überein, die mit „ blogs/ “ beginnen, mit Ausnahme von sich selbst, wie z. B. http://www.microsystools.com/blogs/sitemap-generator/.
- Regulärer Ausdruck:
- :: blog (s?) / gleicht relative Pfade mit Regex ab, z. B. http://www.microsystools.com/ blogs/ und http://www.microsystools.com/ blog/.
- :: blogs/ (2007|2008) / gleicht relative Pfade mit Regex ab, z. B. http://www.microsystools.com/blogs/ 2007/ und http://www.microsystools.com/blogs/ 2008/.
- :: blogs/ .*? Das Schlüsselwort stimmt mit relativen Pfaden mit Regex überein, z. B. http://www.microsystools.com/blogs/category/products/a1-keyword-research/.
- :: ^$ gleicht den leeren relativen Pfad (dh das Stammverzeichnis) mit einem regulären Ausdruck wie http://www.microsystools.com/ ab.
Aus den obigen Beispielen ist Folgendes ersichtlich:
- : allein = besondere Übereinstimmung.
- : beim Start = Pfade stimmen überein.
- : am Anfang und * am Ende = sorgt dafür, dass Pfade in Unterpfade übereinstimmen.
- :: beim Start = Übereinstimmung mit regulären Ausdrücken.
- Keine der oben genannten, normale Zeichenfolgentextübereinstimmung.
So fügen Sie ein Listenfilterelement im Dropdown-Menü hinzu: Geben Sie es ein und verwenden Sie die Schaltfläche [+].
So entfernen Sie ein Listenfilterelement im Dropdown: Wählen Sie es aus und verwenden Sie die Schaltfläche [-].
Sie können weitere Informationen zu den verwendeten Benutzeroberflächensteuerelementen anzeigen
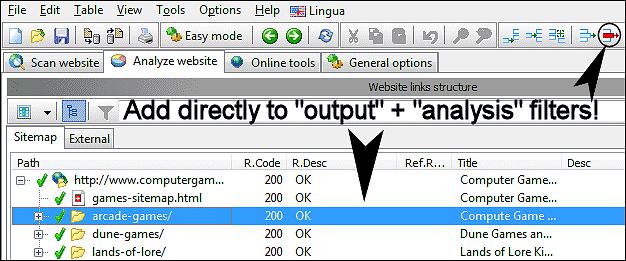
Fügen Sie auf einfache Weise URLs zu Analysefiltern hinzu
Wenn Sie keine der erweiterten Optionen für Analsys-Filter benötigen, können Sie die Schaltfläche „Löschen und filtern“ verwenden, nachdem Sie das Crawlen einer Site abgeschlossen haben. Dies erleichtert die Optimierung der Einstellungen und die Begrenzung der Anzahl der analysierten Seiten für das nächste Mal, wenn Sie die Website crawlen müssen.