|
|

Crawler behandelt Website-Plattformen und -Probleme
Der Crawler in A1 Keyword Research ist wie die meisten Website-Crawler: Er ist gleichgültig gegenüber der Back-End-Plattform, die von der Website verwendet wird. Es spielt keine Rolle, welcher Warenkorb oder welche serverseitige Sprache, wie PHP oder ASP, auf der Website verwendet wird.
Ihr Website-Typ und Server spielen keine Rolle
URL-Rewriting und Ähnliches
Ihre Website kann problemlos virtuelle Verzeichnisse oder URL-Rewriting verwenden. Viele Leute verwenden Apache mod_rewrite, um virtuelle Verzeichnisse und URLs zu erstellen. Ähnliche Lösungen gibt es für fast alle Webserver-Lösungen.
Aus Crawler-Sicht können Websites virtuelle Verzeichnisse und URLs sicher verwenden. Browser, Suchmaschinen-Bots usw. betrachten Ihre Website von außen. Sie wissen nicht, wie Ihre URL-Struktur implementiert ist. Sie können nicht erkennen, ob Seiten oder Verzeichnisse physisch oder virtuell sind.
Serverseitige Sprache und HTML-Webseiten
Auf einer modernen Website besteht oft kaum oder gar keine Korrelation zwischen den URL-„Dateinamen“ und den zugrunde liegenden Daten, einschließlich der Art und Weise, wie diese generiert, gespeichert und abgerufen werden. Es spielt keine Rolle, ob eine Website Cold Fusion, ASP.Net, JSP, PHP oder ähnliches als serverseitige Programmiersprache verwendet. Website-Crawler sehen nur den clientseitigen Code (HTML/CSS/Javascript), der vom Code und den Datenbanken auf dem Server generiert wird.
Hinweis: In den Einstellungen kann der Crawler in unserem Site-Analysetool so eingestellt werden, dass er URLs mit bestimmten Dateierweiterungen und MIME-Inhaltstypen akzeptiert/ignoriert. Wenn Sie Probleme haben, lesen Sie, wie Sie alle Seiten und Links finden.
Dynamisch erstellte Inhalte auf dem Server
Websites, die mithilfe serverseitiger Skripte und Datenbanken dynamisch Seiteninhalte generieren, werden von Site-Crawlern und Robots problemlos gecrawlt.
Hinweis: Einige Suchmaschinen-Robots verlangsamen möglicherweise das Crawlen von URLs mit ?. Dies liegt jedoch vor allem daran, dass Suchmaschinen besorgt sind, indem sie Ressourcen für das Crawling vieler URLs mit automatisch generierten Inhalten ausgeben. Um dies zu mildern, können Sie auf Ihrer Website Mod Rewrite oder ähnliches verwenden.
Hinweis: Unserer Keyword-Recherche und der MiggiBot-Crawler-Engine ist das Aussehen von URLs egal.
Mobile Websites
Viele Websites verwenden heutzutage responsive und adaptive Layouts, die sich mithilfe clientseitiger Technologien, z. B. CSS und Javascript, im Browser anpassen.
Einige Websites verfügen jedoch über spezielle Website-URLs für:
- Funktionstelefone, die nur WAP und ähnliche alte Technologien unterstützen.
- Smartphones mit Browsern, die Desktop-Browsern sehr ähnlich sind und Inhalte auf die gleiche Weise wiedergeben.
- Desktop-Computer, Laptops und Tablets, bei denen die Bildschirmfläche und der Sichtbereich größer sind.
Im Allgemeinen wissen solche für Mobilgeräte optimierten Websites, dass sie für mobile Geräte optimierte Inhalte ausgeben müssen, indem sie entweder:
- Gehen Sie davon aus, dass Inhalte immer für eine bestimmte Gruppe mobiler Geräte, z. B. Smartphones, optimiert ausgegeben werden sollen.
- Führen Sie serverseitige Überprüfungen des vom Crawler oder Browser an ihn übergebenen Benutzeragenten durch. Wenn dann ein mobiles Gerät identifiziert wird, leitet es entweder zu einer neuen URL weiter oder gibt einfach für mobile Geräte optimierte Inhalte aus.
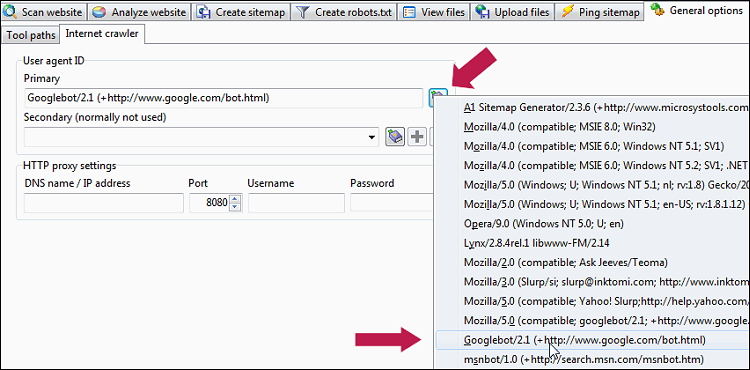
Wenn Sie möchten, dass der Crawler von A1 Keyword Research die mobilen Inhalte und URLs sieht, die Ihre Website auf Mobilgeräten ausgibt, ändern Sie einfach die Einstellung Allgemeine Optionen und Tools | Internet-Crawler | Benutzeragenten-ID zu einer, die von gängigen Mobilgeräten verwendet wird, z. B. diese:
Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, wie Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19.
Sie können dasselbe mit den meisten Desktop-Browsern tun, indem Sie ein User-Agent-Switcher-Plugin installieren. Dadurch können Sie den von Ihrer Website an mobile Browser zurückgegebenen Code überprüfen.
Hinweis: Wenn Ihre für Mobilgeräte optimierte Website eine Mischung aus clientseitigen und serverseitigen Technologien wie AJAX verwendet, um den Benutzeragenten zu erkennen und darauf basierende Inhalte zu ändern, funktioniert sie auf vielen Website-Crawlern nicht mehr, einschließlich, zumindest seit September 2014 , A1 Keyword Research. Es funktioniert jedoch in den meisten Browsern, da sie Javascript- Code ausführen/ausführen, der den Browser nach der Benutzeragenten-ID abfragen kann.
AJAX-Websites
Wenn Ihre Website AJAX verwendet, eine Technologie, bei der Javascript mit dem Server kommuniziert und den Inhalt im Browser ändert, ohne die URL-Adresse zu ändern, sollten Sie wissen, dass die Crawlbarkeit von der genauen Implementierung abhängt.
Erklärung von Fragmenten in URLs:
- Page-relative-fragments: Relative Links innerhalb einer Seite:
http://example.com/somepage#relative-page-link - AJAX-Fragmente: clientseitiges Javascript, das serverseitigen Code abfragt und Inhalte im Browser ersetzt:
http://example.com/somepage#lookup-replace-data - AJAX-fragments-Google-initiative: Teil der Google-Initiative „Making AJAX Applications Crawlable “:
http://example.com/somepage#!lookup-replace-data
Diese Lösung wurde inzwischen von Google selbst abgelehnt. Weitere Informationen finden Sie unter:
https://developers.google.com/webmasters/ajax-crawling/docs/getting-started
https://developers.google.com/webmasters/ajax-crawling/docs/pecification
Wenn Sie diese Lösung verwenden, werden URLs angezeigt, die#!enthalten. und_escaped_fragment_beim Crawlen.
Tipp: So helfen Sie beim erfolgreichen Crawlen von AJAX-Websites:
- Wählen Sie unter Website scannen | eine AJAX-fähige Crawler-Option aus Raupenmotor.
- Aktivieren Sie die Option Website scannen | Crawler-Optionen | Versuchen Sie, in Javascript zu suchen.
- Aktivieren Sie die Option Website scannen | Crawler-Optionen | Versuchen Sie, in JSON zu suchen.
Überprüfen Sie die HTML-Ausgabe der Website für Crawler und Browser
Normalerweise verschleiern Websites niemals Inhalte basierend auf der Benutzeragentenzeichenfolge und der IP-Adresse. Durch Festlegen der Useragent-ID können Sie jedoch die HTML-Quelle überprüfen, die Suchmaschinen und Browser beim Abrufen von Seiten Ihrer Website sehen.
Hinweis: Dies kann auch verwendet werden, um zu testen, ob eine Website korrekt auf einen Crawler/Browser reagiert, der sich als mobil identifiziert.
Hinweis: Dies kann auch verwendet werden, um zu testen, ob eine Website korrekt auf einen Crawler/Browser reagiert, der sich als mobil identifiziert.
So scannen Sie Ihre Website erfolgreich und vollständig
Wenn Probleme beim Crawlen von Websites auftreten, sollten Sie die Antworten zum Auffinden aller Links und Seiten bei Website-Scans lesen.
Sie sollten außerdem sicherstellen, dass A1 Keyword Research nicht durch eine Firewall oder Internet-Sicherheitssoftware blockiert wird.
Sie sollten außerdem sicherstellen, dass A1 Keyword Research nicht durch eine Firewall oder Internet-Sicherheitssoftware blockiert wird.
Problematische Websites und spezifische Website-Plattformen
Filterung und/oder Drosselung der Website-Bandbreite
Einige wenige Website-Plattformen und -Module ergreifen Maßnahmen gegen Crawler, die sie nicht kennen, um Bandbreite und Servernutzung für echte Besucher und Suchmaschinen zu reservieren. Hier ist eine Liste bekannter Lösungen für diese Website-Plattformen:
- Joomla-Websites: Joomla-Keyword-Recherche.
- NetSuite-Websites: NetSuite-Keyword-Recherche.
- e107 CMS-Websites: e107-Keyword-Recherche.
- Ebay-Shop-Websites: Ebay-Keyword-Recherche.
Wenn Sie versuchen, ein Forum zu crawlen, lesen Sie unseren Leitfaden zum optimalen Crawlen von Foren und Blogs mit Keyword-Recherche.
Die Website sendet unregelmäßig den falschen Seiteninhalt
Wir haben einige Fälle gesehen, in denen die Website, der Server, das CDN, das CMS oder das Cache-System unter einem Fehler litten und beim Crawlen den falschen Inhalt der Ausgabeseite sendeten.
Um ein solches Problem nachzuweisen und zu diagnostizieren, laden Sie A1 Website Download wie folgt herunter und konfigurieren Sie es:
- Website scannen | festlegen Download-Optionen | Konvertieren Sie URL-Pfade in heruntergeladenen Inhalten in „Keine Konvertierung“.
- Website scannen | aktivieren Datenerfassung | Speichern Sie Weiterleitungen und Links von und zu allen Seiten.
- Aktivieren Sie alle Optionen unter Website scannen | Webmaster-Filter.
Sie können nun den heruntergeladenen Quellcode der Seite mit dem vergleichen, was im A1-Website-Download gemeldet wird, und sehen, ob der Webserver/die Website korrekte oder falsche Inhalte an die A1-Crawler-Engine gesendet hat.
Um ein solches Problem ohne Zugriff auf die Website und den Webserver-Code zu lösen, versuchen Sie, einige der weiter unten vorgeschlagenen Konfigurationen zu verwenden.
Allgemeine Lösungen für das Crawlen problematischer Websites
Wenn Sie auf eine Website stoßen, die Crawler-Anfragen drosselt, bestimmte Benutzeragenten blockiert oder sehr langsam ist, erhalten Sie häufig Antwortcodes wie:
Um diese Probleme zu lösen, versuchen Sie Folgendes:
Hinweis: Sollten weiterhin Probleme auftreten, können Sie die oben genannten Schritte mit Folgendem kombinieren:
Hinweis: Wenn Ihre IP-Adresse blockiert wurde, können Sie versuchen , Allgemeine Optionen und Tools | zu verwenden Internet-Crawler | HTTP-Proxy-Einstellungen. Die Proxy-Unterstützung hängt davon ab, welche HTTP-Engine unter Website scannen | ausgewählt wurde Raupenmotor.
Hinweis: Wenn es sich bei dem Problem um Zeitüberschreitungsfehler handelt, können Sie auch versuchen, wiederholte Crawls mit der Resume-Scan- Funktion durchzuführen.
Sie können auch unsere Standardprojektdatei für problematische Websites herunterladen, da Sie häufig dieselben Lösungen auf eine Vielzahl von Websites anwenden können.
- 403 Verboten
- 503 Service ist vorübergehend nicht verfügbar
- -5: TimeoutConnectError
- -6: TimeoutReadError
Um diese Probleme zu lösen, versuchen Sie Folgendes:
- Website scannen | festlegen Raupenmotor | Max. gleichzeitige Verbindungen zu einem.
- Crawler-Motor einstellen | Erweiterte Engine-Einstellungen | Standardmäßig werden GET-Anfragen aktiviert/aktiviert.
- Anschließend ggf. den Webcrawler als Suchmaschine oder als surfenden Nutzer ausweisen lassen.
- Als „Benutzer, der auf der Website surft“ identifizieren:
- Allgemeine Optionen und Tools festlegen | Internet-Crawler | Benutzeragenten-ID für Mozilla/4.0 (kompatibel; MSIE 7.0; Win32).
- Website scannen | festlegen Webmaster-Filter | Laden Sie „robots.txt“ herunter, um es zu deaktivieren/deaktivieren.
- In Website scannen | Die Crawler-Engine erhöht die Zeitspanne zwischen aktiven Verbindungen.
- Optional:: Website scannen | festlegen Crawler-Engine zu HTTP mithilfe der WinInet-Engine und -Einstellungen (Internet Explorer)
- Als „Suchmaschinen-Crawler“ identifizieren:
- Allgemeine Optionen und Tools festlegen | Internet-Crawler | User-Agent-ID für Googlebot/2.1 (+http://www.google.com/bot.html) oder eine andere Suchmaschinen-Crawler-ID.
- Website scannen | festlegen Webmaster-Filter | Laden Sie „robots.txt“ herunter, um es zu aktivieren/aktivieren.
- Website scannen | festlegen Webmaster-Filter | Befolgen Sie die Anweisung „disallow“ der Datei „robots.txt“, um sie zu aktivieren/aktivieren.
- Website scannen | festlegen Webmaster-Filter | Befolgen Sie die Anweisung „crawl-delay“ der Datei „robots.txt“, um sie zu aktivieren/aktivieren.
- Website scannen | festlegen Webmaster-Filter | Befolgen Sie den Noindex „Meta“-Tag „Robots“, um ihn zu aktivieren/aktivieren.
- Website scannen | festlegen Webmaster-Filter | Befolgen Sie das „Meta“-Tag „Robots“ nofollow, um es zu aktivieren/aktivieren.
- Website scannen | festlegen Webmaster-Filter | Befolgen Sie das „a“-Tag „rel“ nofollow, um aktiviert/aktiviert zu werden.
- Als „Benutzer, der auf der Website surft“ identifizieren:
Hinweis: Sollten weiterhin Probleme auftreten, können Sie die oben genannten Schritte mit Folgendem kombinieren:
- Website scannen | festlegen Raupenmotor | Crawl-Verzögerung in Millisekunden zwischen Verbindungen auf mindestens 3000.
Hinweis: Wenn Ihre IP-Adresse blockiert wurde, können Sie versuchen , Allgemeine Optionen und Tools | zu verwenden Internet-Crawler | HTTP-Proxy-Einstellungen. Die Proxy-Unterstützung hängt davon ab, welche HTTP-Engine unter Website scannen | ausgewählt wurde Raupenmotor.
Hinweis: Wenn es sich bei dem Problem um Zeitüberschreitungsfehler handelt, können Sie auch versuchen, wiederholte Crawls mit der Resume-Scan- Funktion durchzuführen.
Sie können auch unsere Standardprojektdatei für problematische Websites herunterladen, da Sie häufig dieselben Lösungen auf eine Vielzahl von Websites anwenden können.
