|
|

Recrawl und Resume Crawl in der Keyword-Recherche
Einige Webserver sind träge oder verweigern unbekannten Crawlern wie A1 Keyword Research den Zugriff. Um sicherzustellen, dass alles gecrawlt wird, können Sie die „Fortsetzen“-Funktion im Keyword-Recherche-Tool verwenden.
Setzen Sie den Scan fort, um URLs mit Fehlerantwortcodes zu reparieren
Es kann viele Gründe geben, einen Website-Scan fortzusetzen, nachdem er gestoppt wurde. Ein Grund dafür ist, dass Webserver normalerweise überlastet sind und mit Fehlercodes für URLs reagieren
Eine einfache Möglichkeit, festzustellen, ob auf der gesamten Website noch Fehler vorhanden sind, besteht darin, die Verzeichnisübersicht für das Stammverzeichnis/die Stammdomäne anzuzeigen.
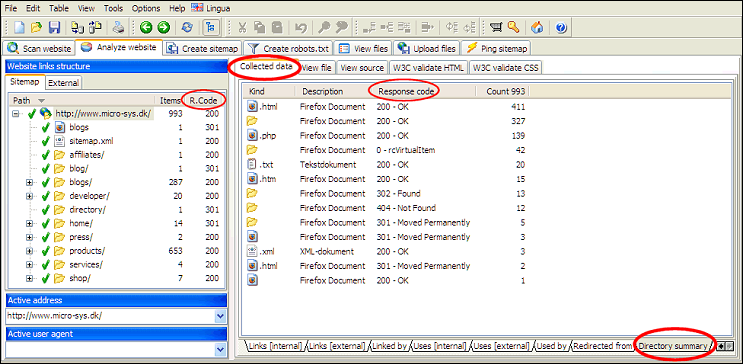
Nutzen Sie dann die Lebenslauffunktion von A1 Keyword Research, um diese URLs erneut zu crawlen. Fahren Sie damit fort, bis keine Fehler mehr vorhanden sind.

Während der Website-Scan läuft, können Sie jederzeit:
So verwenden Sie die Website-Scan- und Crawl-Resume-Funktion:
- 503 Service ist vorübergehend nicht verfügbar
- 500: Interner Serverfehler
- -4: CommError
Eine einfache Möglichkeit, festzustellen, ob auf der gesamten Website noch Fehler vorhanden sind, besteht darin, die Verzeichnisübersicht für das Stammverzeichnis/die Stammdomäne anzuzeigen.
Nutzen Sie dann die Lebenslauffunktion von A1 Keyword Research, um diese URLs erneut zu crawlen. Fahren Sie damit fort, bis keine Fehler mehr vorhanden sind.
Während der Website-Scan läuft, können Sie jederzeit:
- Unterbrechen und stoppen Sie den Website-Scan.
- Setzen Sie den Website-Scan fort und setzen Sie ihn fort.
So verwenden Sie die Website-Scan- und Crawl-Resume-Funktion:
- Das Anhalten eines Scans ist dasselbe wie das Stoppen eines Scans. Wenn der Scan gestoppt/angehalten wird oder die Internetverbindung unterbrochen wird, können Sie fortfahren.
- Um einen Scan fortzusetzen, müssen Sie die Option „Fortsetzen“ aktivieren. (In alten Versionen war dies eine Drucktaste .) Klicken Sie dann auf die Schaltfläche „Scan starten“.
- Sie können das Projekt speichern. Dies ermöglicht Ihnen, das Projekt zu einem späteren Zeitpunkt zu laden. Anschließend können Sie das Projekt fortsetzen.
Warum das Pausieren von Website-Crawlings manchmal URLs entfernt
Sie können das erneute Crawlen bestimmter URLs erzwingen, indem Sie deren Statusflags in der Website-Analyse ändern, bevor Sie mit dem Website-Scan fortfahren.
Je nach Programm und Version besteht das Standardverhalten nach Abschluss eines Website-Scans aus irgendeinem Grund, z. B. einer Pause, darin, dass alle URLs entfernt werden, die von Webmaster-Filtern wie robots.txt- Datei- und Ausgabefiltern ausgeschlossen werden.
Das obige Verhalten ist nicht immer erwünscht, da es bedeutet, dass der Website-Crawler Zeit damit verbringt, zuvor getestete URLs erneut zu entdecken. Lösen:
Wenn gefilterte/ausgeschlossene URLs nicht aus den Ergebnissen des Website-Scans entfernt werden, können Sie deren Crawler- und URL-Status-Flags anzeigen:
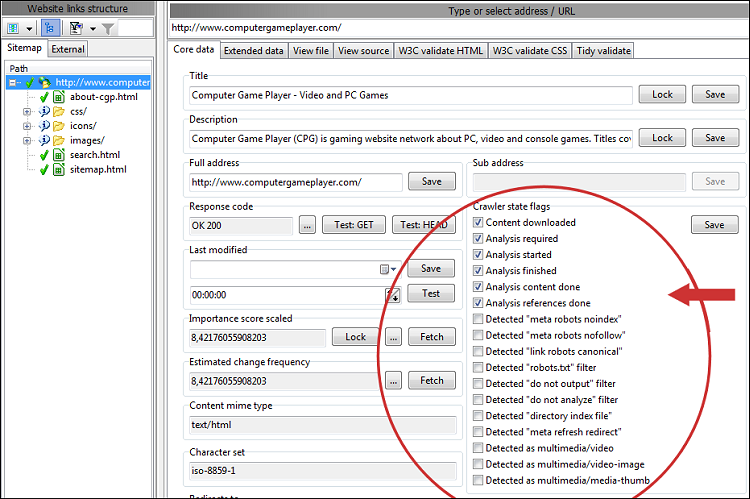
Je nach Programm und Version besteht das Standardverhalten nach Abschluss eines Website-Scans aus irgendeinem Grund, z. B. einer Pause, darin, dass alle URLs entfernt werden, die von Webmaster-Filtern wie robots.txt- Datei- und Ausgabefiltern ausgeschlossen werden.
Das obige Verhalten ist nicht immer erwünscht, da es bedeutet, dass der Website-Crawler Zeit damit verbringt, zuvor getestete URLs erneut zu entdecken. Lösen:
- Ältere Versionen:
- Deaktivieren Sie Website scannen | Crawler-Optionen | Wenden Sie die Filter „Webmaster“ und „Ausgabe“ an, nachdem der Website-Scan beendet wurde
- Neuere Versionen:
- Deaktivieren Sie Website scannen | Ausgabefilter | Nachdem der Website-Scan beendet wurde: Ausgeschlossene URLs entfernen
- Deaktivieren Sie Website scannen | Webmaster-Filter | Nachdem der Website-Scan beendet wurde: URLs mit noindex/disallow entfernen
Wenn gefilterte/ausgeschlossene URLs nicht aus den Ergebnissen des Website-Scans entfernt werden, können Sie deren Crawler- und URL-Status-Flags anzeigen:
Resume Website Scan analysiert URLs erneut
Die Art und Weise, wie das Website-Crawling intern funktioniert, haben wir:
Dies bedeutet, dass alle Seiten, auf denen nicht alle Links aufgelöst wurden, bei der Wiederaufnahme des Scanvorgangs erneut analysiert werden müssen. Um dieses Problem zu vermeiden, kann der Website-Crawler HEAD- Anfragen verwenden, um Links zu verifizierten URLs schnell aufzulösen. Während dies beim Crawlen zum Server zu einigen zusätzlichen Anfragen führt (wenn auch nur in geringem Umfang), wird die Verschwendung bei Verwendung der Resume-Funktion auf nahezu Null reduziert.
Um dies zu konfigurieren, deaktivieren Sie: Website scannen > Crawler-Engine > Standardmäßig GET für Seitenanfragen
- Gefundene URLs: Dies sind URLs, die aufgelöst und getestet wurden.
- Analysierte Inhalts-URLs: Der Inhalt dieser URLs (Seiten) wurde analysiert.
- Analysierte Referenz-URLs: Die im Inhalt dieser URLs (Seiten) gefundenen Links wurden aufgelöst.
Dies bedeutet, dass alle Seiten, auf denen nicht alle Links aufgelöst wurden, bei der Wiederaufnahme des Scanvorgangs erneut analysiert werden müssen. Um dieses Problem zu vermeiden, kann der Website-Crawler HEAD- Anfragen verwenden, um Links zu verifizierten URLs schnell aufzulösen. Während dies beim Crawlen zum Server zu einigen zusätzlichen Anfragen führt (wenn auch nur in geringem Umfang), wird die Verschwendung bei Verwendung der Resume-Funktion auf nahezu Null reduziert.
Um dies zu konfigurieren, deaktivieren Sie: Website scannen > Crawler-Engine > Standardmäßig GET für Seitenanfragen
Erzwingen Sie das erneute Crawlen bestimmter URLs
Wenn Sie nicht die gesamte Website neu crawlen möchten, Resume jedoch nicht anwendbar ist, da alle URLs analysiert wurden, können Sie Folgendes tun:
- Wählen Sie auf der linken Seite, wo alle URLs aufgelistet sind, diejenigen aus, die Sie erneut crawlen lassen möchten.
- Deaktivieren Sie unter „Crawler-Statusflags“ alle Flags „Analyse xxx“ mit Ausnahme von „Analyse erforderlich“.
- Klicken Sie im Bereich „Crawler State Flags“ auf die Schaltfläche „Speichern“.
- Aktivieren Sie unter Website scannen die Option Lebenslauf (vollständig).
- Starten Sie den Scan.
Weitere URLs finden Sie unter Website-Scans
Wenn Sie Schwierigkeiten haben, alle URLs in Website-Crawls einzubeziehen, ist es wichtig, zunächst die obige Empfehlung zu befolgen. Der Grund dafür ist, dass URLs mit Fehlerantwortcodes nicht nach Links gecrawlt werden. Wenn Sie dieses Problem lösen, erhalten Sie in der Regel auch mehr URLs.
Weitere Anregungen und Tipps finden Sie in unserem Hilfeartikel zum Website-Crawling.
Weitere Anregungen und Tipps finden Sie in unserem Hilfeartikel zum Website-Crawling.
Vollständig fortsetzen versus „Fehler beheben“ versus „Neues Crawlen“.
- Lebenslauf (vollständig):
- Behält alle URLs aus früheren Scans.
- Crawlt und analysiert alle URLs, die nicht als vollständig analysiert gekennzeichnet sind.
- Wenn neue URLs gefunden werden, werden diese ebenfalls gecrawlt.
- Fortsetzen (Fehler beheben):
- Behält alle URLs aus früheren Scans.
- Testet alle URLs, die beim Crawlen irgendwie auf einen Fehler reagiert haben.
- Recrawl (vollständig) – auch Refresh genannt:
- Behält alle URLs aus früheren Scans.
- Crawlt und analysiert alle URLs. Hierzu zählen auch URLs, deren Crawling-Status-Flags keine Analyse erforderlich enthalten.
In Zukunft ist es möglich, dass beim erneuten Crawlen URLs priorisiert werden, z. B. nach Wichtigkeit, Zeitpunkt der letzten Überprüfung, Häufigkeit von Seitenänderungen usw. - Wenn neue URLs gefunden werden, werden diese ebenfalls gecrawlt.
- Nützlich in Fällen, in denen Sie Inhalte gesperrt haben, z. B. den Seitentitel für eine bestimmte URL, und sicherstellen möchten, dass die gesperrten Daten erhalten bleiben.
Verwenden Sie die Sperrschaltflächen neben verschiedenen Daten wie Titeln.
- Erneutes Crawlen (nur aufgeführt):
- Wie Recrawl, analysiert jedoch keine neuen URLs und fügt diese nicht in die Scanergebnisse ein.
- Keine der oben genannten Optionen aktiviert:
- Die Standardeinstellung und wird in den meisten Fällen empfohlen.
