|
|

Website Robots.txt, Noindex, Nofollow und Canonical
A1 Keyword Research bietet optionale Unterstützung für die Einhaltung von Robots-Textdateien, Noindex und Nofollow in Meta-Tags sowie Nofollow in Link-Tags.
Keyword-Recherche und Webmaster-Crawling-Filter
Der Website-Crawler von A1 Keyword Research verfügt über viele Tools und Optionen, um sicherzustellen, dass er komplexe Websites scannen kann. Einige davon umfassen die vollständige Unterstützung für Robots-Textdateien, Noindex und Nofollow in Meta-Tags sowie Nofollow in Link-Tags.
Tipp: Durch das Herunterladen von robots.txt werden Sie häufig von Webservern und Analysesoftware als Website-Crawler-Roboter identifiziert.
Die meisten dieser Optionen finden Sie unter Website scannen | Webmaster-Filter.

In diesem Zusammenhang können Sie auch steuern, wie sie angewendet werden:
Wenn Sie die Crawler-Funktion zum Anhalten und Fortsetzen verwenden, können Sie vermeiden, dass dieselben URLs wiederholt gecrawlt werden, indem Sie sie alle zwischen den Scans behalten.
Tipp: Durch das Herunterladen von robots.txt werden Sie häufig von Webservern und Analysesoftware als Website-Crawler-Roboter identifiziert.
Die meisten dieser Optionen finden Sie unter Website scannen | Webmaster-Filter.
In diesem Zusammenhang können Sie auch steuern, wie sie angewendet werden:
- Website scannen deaktivieren | Webmaster-Filter | Nachdem der Website-Scan beendet wurde: URLs mit noindex/disallow entfernen.
Wenn Sie die Crawler-Funktion zum Anhalten und Fortsetzen verwenden, können Sie vermeiden, dass dieselben URLs wiederholt gecrawlt werden, indem Sie sie alle zwischen den Scans behalten.
HTML-Code für Canonical, NoIndex, NoFollow und mehr
- Kanonisch:
<link rel="canonical" href="http://www.example.com/list.php?sort=az" />
Dies ist in Fällen nützlich, in denen zwei verschiedene URLs denselben Inhalt liefern. Informieren Sie sich über doppelte URLs, da es möglicherweise bessere Lösungen als die Verwendung kanonischer Anweisungen, z. B. Weiterleitungen, gibt. Die Unterstützung hierfür wird durch die Option gesteuert: Website scannen | Webmaster-Filter | Befolgen Sie das kanonische „link“-Tag „rel“. - NoFollow:
<a href="http://www.example.com/" rel="nofollow">schlechter Link</a> und <meta name="robots" content="nofollow" />
Die Unterstützung hierfür wird durch folgende Optionen gesteuert: Website scannen | Webmaster-Filter | Befolgen Sie das „a“-Tag „rel“ nofollow und scannen Sie die Website | Webmaster-Filter | Befolgen Sie das „Meta“-Tag „Robots“ nofollow. - NoIndex:
<meta name="robots" content="noindex" />
Die Unterstützung hierfür wird durch folgende Optionen gesteuert: Website scannen | Webmaster-Filter | Befolgen Sie das „meta“-Tag „robots“ noindex. - Meta-Weiterleitung:
<meta http-equiv="refresh" content="0;url=https://example.com" />
Die Unterstützung hierfür wird durch die Option gesteuert: Website scannen | Crawler-Optionen | Erwägen Sie eine Meta-Aktualisierung von 0 Sekunden für die Weiterleitung. - Javascript-Links und Referenzen:
<button onclick="myLinkClick()">Beispiel</button>
Die Unterstützung hierfür wird durch Optionen gesteuert:- Website scannen | Crawler-Optionen | Versuchen Sie, in Javascript zu suchen.
- Website scannen | Crawler-Optionen | Versuchen Sie, in JSON zu suchen.
Tipp: Sie können unter Website scannen | auch einen AJAX- fähigen Crawler auswählen Raupenmotor.
Listen- und Analysefilter ein- und ausschließen
Weitere Informationen zu Analyse- und Ausgabefiltern finden Sie in unserer Online-Hilfe für A1 Keyword Research.
Unterstützung für Übereinstimmungsverhalten und Platzhalter in Robots.txt
Das Match- Verhalten im Website-Crawler von A1 Keyword Research ähnelt dem der meisten Suchmaschinen.
Unterstützung für Platzhaltersymbole in der robots.txt- Datei:
Der Crawler in unserem Keyword-Recherche-Tool berücksichtigt die folgenden Benutzeragenten-IDs in der robots.txt- Datei:
Alle gefundenen Disallow- Anweisungen in robots.txt werden in A1 Keyword Research intern sowohl in Analyse- als auch in Ausgabefilter umgewandelt.
Unterstützung für Platzhaltersymbole in der robots.txt- Datei:
- Standard: Übereinstimmung vom Anfang bis zur Länge des Filters.
gre passt zu: greyfox, greenfox und green/fox. - Platzhalter *: Entspricht einem beliebigen Zeichen, bis eine weitere Übereinstimmung möglich wird.
gr*fox passt zu: greyfox, greyfox, Growl-fox und green/fox.
Tipp: Platzhalterfilter in robots.txt sind oft falsch konfiguriert und verursachen Crawling-Probleme.
Der Crawler in unserem Keyword-Recherche-Tool berücksichtigt die folgenden Benutzeragenten-IDs in der robots.txt- Datei:
- Genaue Übereinstimmung mit dem Benutzeragenten, ausgewählt in: Allgemeine Optionen und Tools | Internet-Crawler | Benutzeragenten-ID.
- Benutzeragent: A1-Schlüsselwortrecherche, ob der Produktname in der oben genannten HTTP-Benutzeragentenzeichenfolge enthalten ist.
- Benutzeragent: miggibot, wenn der Name der Crawler-Engine in der oben genannten HTTP-Benutzeragentenzeichenfolge enthalten ist.
- Benutzeragent: *.
Alle gefundenen Disallow- Anweisungen in robots.txt werden in A1 Keyword Research intern sowohl in Analyse- als auch in Ausgabefilter umgewandelt.
Überprüfen Sie die Ergebnisse nach dem Website-Scan
Alle Status-Flags aller vom Crawler erkannten URLs anzeigen – hierfür werden die in den Webmaster-Filtern, Analysefiltern und Ausgabefiltern festgelegten Optionen verwendet.
Alternativ nutzen Sie die Option Website scannen | Crawler-Optionen | Verwenden Sie spezielle Antwortcodes, um Zustände als Antwortcodes widerzuspiegeln.
Um Details zu einer bestimmten URL zu erhalten, wählen Sie diese aus und sehen Sie sich alle Informationen unter Erweiterte Daten | an Details, Erweiterte Daten | Verlinkt von und ähnlich:
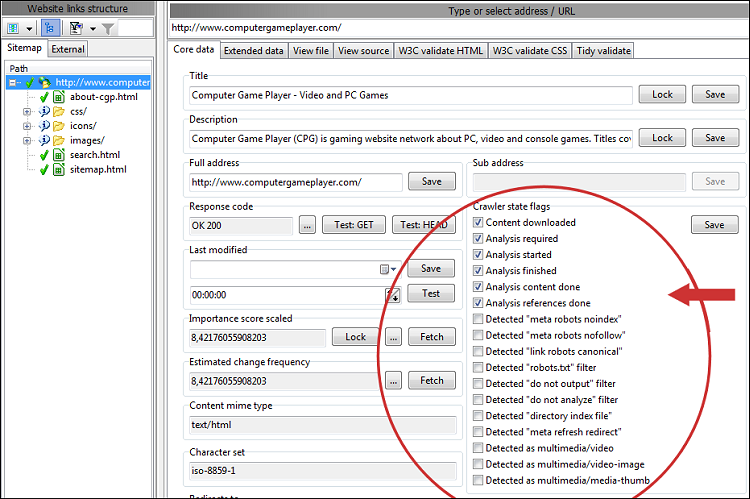
Alternativ nutzen Sie die Option Website scannen | Crawler-Optionen | Verwenden Sie spezielle Antwortcodes, um Zustände als Antwortcodes widerzuspiegeln.
Um Details zu einer bestimmten URL zu erhalten, wählen Sie diese aus und sehen Sie sich alle Informationen unter Erweiterte Daten | an Details, Erweiterte Daten | Verlinkt von und ähnlich:
