|
|

Sprog, skrifttyper, Unicode og kodesider
A1 Website Scraper og information om skrifttyper, tegntavler, tegnsæt og Unicode inklusive fx UTF-8
Windows-systemskrifttype og Unicode-præsentation
For korrekt at se alle Unicode-tegn i Windows XP og derunder, skal du muligvis enten :
Du skal muligvis også sørge for at have alle de nødvendige Unicode-skrifttyper og dele installeret:

- Skift Windows-systemskrifttype til en fuld Unicode-skrifttype.
- I filen muc.ini (placeret i programmets installationsmappe) ved tasten FontOverride kan du kontrollere, hvilke skrifttyper A1 Website Scraper vil forsøge at bruge:
[Diverse]
DataAccess=auto
FontOverride=Arial Unicode MS, Lucida Sans Unicode, Segoe UI
Du kan eksperimentere med skrifttyperne i forskellig rækkefølge for at finde den skrifttype, du bedst kan lide.
Du skal muligvis også sørge for at have alle de nødvendige Unicode-skrifttyper og dele installeret:
Følgende hjælp er primært relevant for gamle A1-websideskraberversioner
Det meste af hjælpesidens indhold nedenfor blev skrevet i 2007 og er hovedsageligt relevant for gamle versioner af A1 Website Scraper
I løbet af 2010 med udgivelsen af versionen af A1 -værktøjerne version 3.x blev komplet intern support af Unicode i vores webstedsskrabersoftware fuldført. Med Unicode-understøttelse fuldt implementeret, behøver du normalt ikke længere at konfigurere Windows ud over ovenstående.
Bemærk: Følgende ting gælder dog stadig for 2015 version 7.x og muligvis også fremtidige versioner:
I løbet af 2010 med udgivelsen af versionen af A1 -værktøjerne version 3.x blev komplet intern support af Unicode i vores webstedsskrabersoftware fuldført. Med Unicode-understøttelse fuldt implementeret, behøver du normalt ikke længere at konfigurere Windows ud over ovenstående.
Bemærk: Følgende ting gælder dog stadig for 2015 version 7.x og muligvis også fremtidige versioner:
- Følgende eksekverbare filer tilføjes under installationen på Windows :
- Scraper_64b_UC.exe / Scraper_64b_W2K.exe / 64 bit unicode eksekverbar til Windows 2000 eller nyere.
- Scraper_32b_UC.exe / Scraper_32b_W2K.exe / 32 bit unicode eksekverbar til Windows 2000 eller nyere.
- Scraper_32b_CP.exe / Scraper_32b_W9xNT4.exe / 32 bit kodetabel eksekverbar til Windows 98 / NT4 eller nyere.
- Den bedst egnede til din computerhardware og dit system gøres automatisk til standard.
- Når du installerer A1 Website Scraper på Windows 95/98/ME/NT4 resulterer dette i en eksekverbar fil, der ikke er Unicode.
Gennemgang af ikke-vestlige eller fjernøstlige sprogwebsteder
Det er i øjeblikket muligt at scanne alle enkeltsprogede (og nogle flersprogede) websteder. Dette omfatter udtrækning af titler, tekst osv.
I øjeblikket gør A1 Website Scraper følgende ved scanning:
Hvis et websted bruger flere sprog, kan du prøve en af følgende løsninger:
I øjeblikket gør A1 Website Scraper følgende ved scanning:
- Støder på et websted, der bruger et eller andet tegnsæt, normalt UTF-8, UTF-16 eller ISO 8859-1.
Det faktiske sprog, der bruges på hjemmesiden, kan fx være engelsk, tysk, arabisk, russisk, kinesisk eller lignende. - Webstedets tekst konverteres til den lokale computer-vindue-konfigurerede kodeside. Dette kræver:
- Det lokale computer Windows tegnsæt indeholder det eller de sprog, der bruges på webstedet.
- Hjemmesiden bruger enten UTF-8, UTF-16 (+ nogle flere) eller den samme/lignende kodetabel som lokal computer.
- Al strengscanning, behandling osv. håndteres i lokal tegntabel, uanset om det er enkelt- eller multibyte-kodet tegnsæt.
- Ved oprettelse af f.eks. UTF-8 XML-filer konverteres al tekst i den lokale tegntabel korrekt til UTF-8.
Hvis et websted bruger flere sprog, kan du prøve en af følgende løsninger:
- Bedst:
- Find og brug en kodeside, der inkluderer understøttelse af alle sprog på webstedet.
- Alternativ:
- Opdelt websted scan op i flere projekter, et for hvert sprog.
- Med hvert webstedsscanningsprojekt skal du sørge for at bruge en passende kodetabel.
Fælles kodesider og de sprog, de indeholder
Der findes mange kodetavler. Nogle er sprogspecifikke. Nogle omfatter flere sprog, normalt beslægtede, f.eks. latin eller kyrillisk.
- ISO 8859-1: Indeholder de fleste vesteuropæiske sprog. Denne (eller lidt anderledes) tegntabel er, hvad de fleste "vestlige" Windows-computere som standard bruger.
- Tegnsæt med kodetabel windows-1252: Meget lig ISO 8859-1.
- ISO 8859-2: Indeholder mange central- og østeuropæiske sprog.
- Tegnsæt i Windows-1250 med tegntabel: Meget lig ISO 8859-2.
- Kodeside windows-1251 tegnsæt: Indeholder kyrilliske sprog (f.eks. russisk) og engelsk.
- KOI-8: Populær russisk kodeside. God til russiske/engelske dokumenter.
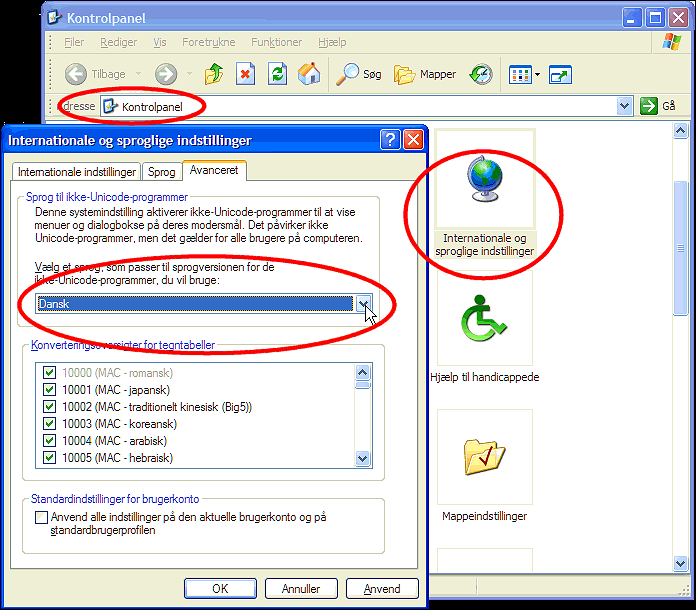
Skift Windows-kodesidesprog, der bruges til ikke-Unicode-programmer
- Åbn Kontrolpanel | Regional og sprog | Avanceret.
- Vælg det sprog, du ønsker at bruge, og klik på OK.
Når A1 Website Scraper vil skifte til Unicode UTF-8 eller UTF-16 internt
Vi bruger i øjeblikket Borland/CodeGear Delphi til Windows 32bit native udvikling. Mens vi har et langsigtet mål om at få vores kildekode til at kompilere med flere udviklerværktøjer og operativsystemplatforme, er Delphi i øjeblikket vores primære værktøj.
Det aktuelle problem er, at Delphi gør det svært at få fuldstændig support til Unicode, selv når du bruger 3. parts løsninger (hvoraf de fleste kun er beskæftiget med kontrol af brugergrænsefladen og ikke strengbehandling som sådan). En mere alvorlig hindring er, at Unicode-løsninger implementeret i Delphi i dag risikerer at skulle udskiftes og omarbejdes den dag, Delphi understøtter Unicode internt i dets klassebiblioteker og native strengdatatype.
Vi har skrevet et næsten komplet fil- og strengabstraktionslag, der kortlægger og har hundredvis af funktionskald, brede og specialiserede. Alle funktioner bruger i øjeblikket den oprindelige delphi-strengbasetype. Dette lag skifter i øjeblikket nogle af dets tilknytninger afhængigt af, hvilken slags tegnsæt-tegnsætkodning, der bruges, enkeltbyte eller DBCS / MBCS.
Når Borland/CodeGear har implementeret sin Unicode-løsning til native Windows-udvikling, højst sandsynligt baseret på enten UTF-8 eller UTF-16, vil vi udvide vores strengabstraktionssystem til at inkludere dette og få fuld intern support til unicode. Trinene til dette vil være:
Det har vi forberedt os på i lang tid. Vi håber dog, du har forståelse for, at der er et stort arbejde og kvalitetssikring forbundet med dette, og vi afventer derfor at se, hvilken vej Borland/CodeGear går med Delphi, inden vi binder de mange mandetimer på den endelige løsning.
I øjeblikket har køreplanen for Delphi komplet Unicode-understøttelse i Delphi "Tiburon" (kodenavn), som er planlagt til første halvdel af 2008. På et tidspunkt før dette, vil vi kende detaljerne i den vej, Borland/CodeGear har valgt til implementering af Unicode-understøttelse. Dette betyder, at vi højst sandsynligt kan implementere de sidste trin af Unicode-support hurtigere end ovenstående dato.
Det aktuelle problem er, at Delphi gør det svært at få fuldstændig support til Unicode, selv når du bruger 3. parts løsninger (hvoraf de fleste kun er beskæftiget med kontrol af brugergrænsefladen og ikke strengbehandling som sådan). En mere alvorlig hindring er, at Unicode-løsninger implementeret i Delphi i dag risikerer at skulle udskiftes og omarbejdes den dag, Delphi understøtter Unicode internt i dets klassebiblioteker og native strengdatatype.
Vi har skrevet et næsten komplet fil- og strengabstraktionslag, der kortlægger og har hundredvis af funktionskald, brede og specialiserede. Alle funktioner bruger i øjeblikket den oprindelige delphi-strengbasetype. Dette lag skifter i øjeblikket nogle af dets tilknytninger afhængigt af, hvilken slags tegnsæt-tegnsætkodning, der bruges, enkeltbyte eller DBCS / MBCS.
Når Borland/CodeGear har implementeret sin Unicode-løsning til native Windows-udvikling, højst sandsynligt baseret på enten UTF-8 eller UTF-16, vil vi udvide vores strengabstraktionssystem til at inkludere dette og få fuld intern support til unicode. Trinene til dette vil være:
- Noget omarbejdelse og kodning af vores strengabstraktionslag. Mængden af arbejde vil afhænge af den rute Borland/CodeGear vælger, fx behovet for konvertering mellem Unicode-typer og den indfødte Delphi "streng"-datatype.
- Udvid alle strengfunktionstilknytninger med Unicode-version(er). Pointen er at undgå at konvertere og omskrive de mange tusinde og dog tusindvis af steder, der kalder disse strengfunktioner.
- Selv med ovenstående vil der være mange kodeområder, der skal gennemgås og ændres lidt.
- Kvalitetssikring, hvilket betyder masser af test.
Det har vi forberedt os på i lang tid. Vi håber dog, du har forståelse for, at der er et stort arbejde og kvalitetssikring forbundet med dette, og vi afventer derfor at se, hvilken vej Borland/CodeGear går med Delphi, inden vi binder de mange mandetimer på den endelige løsning.
I øjeblikket har køreplanen for Delphi komplet Unicode-understøttelse i Delphi "Tiburon" (kodenavn), som er planlagt til første halvdel af 2008. På et tidspunkt før dette, vil vi kende detaljerne i den vej, Borland/CodeGear har valgt til implementering af Unicode-understøttelse. Dette betyder, at vi højst sandsynligt kan implementere de sidste trin af Unicode-support hurtigere end ovenstående dato.
