|
|

Website Robots.txt, Noindex, Nofollow og Canonical
A1 Website Analyzer har valgfri support til at adlyde robottekstfiler, noindex og nofollow i metatags og nofollow i linktags.
Bemærk: Vi har video tutorials:

Selvom disse videodemonstrationer bruger TechSEO360, er de også anvendelige for brugere af A1 Website Analyzer.
Selvom disse videodemonstrationer bruger TechSEO360, er de også anvendelige for brugere af A1 Website Analyzer.
Website Analyzer og Webmaster Crawl-filtre
Webstedscrawleren i A1 Website Analyzer har mange værktøjer og muligheder for at sikre, at den kan scanne komplekse websteder. Nogle af disse inkluderer komplet understøttelse af robottekstfiler, noindex og nofollow i metatags og nofollow i linktags.
Tip: Downloading af robots.txt vil ofte få webservere og analysesoftware til at identificere dig som en webcrawler-robot.
Du kan finde de fleste af disse muligheder på Scan hjemmeside | Webmaster filtre.

I forbindelse med disse kan du også styre, hvordan de bliver anvendt:
Hvis du bruger pause og genoptag crawler-funktionalitet, kan du undgå at få de samme webadresser crawlet gentagne gange ved at gemme dem alle mellem scanninger.
Tip: Downloading af robots.txt vil ofte få webservere og analysesoftware til at identificere dig som en webcrawler-robot.
Du kan finde de fleste af disse muligheder på Scan hjemmeside | Webmaster filtre.
I forbindelse med disse kan du også styre, hvordan de bliver anvendt:
- Deaktiver Scan websted | Webmaster filtre | Når webstedsscanningen stopper: Fjern URL'er med noindex/disallow.
Hvis du bruger pause og genoptag crawler-funktionalitet, kan du undgå at få de samme webadresser crawlet gentagne gange ved at gemme dem alle mellem scanninger.
HTML-kode til Canonical, NoIndex, NoFollow og mere
- Kanonisk:
<link rel="canonical" href="http://www.example.com/list.php?sort=az" />
Dette er nyttigt i tilfælde, hvor to forskellige URL'er giver samme indhold. Overvej at læse om duplikerede URL'er, da der kan være bedre løsninger end at bruge kanoniske instruktioner, fx omdirigeringer. Support til dette styres af muligheden: Scan hjemmeside | Webmaster filtre | Adlyd "link" tag "rel" kanonisk. - Ingen følger:
<a href="http://www.example.com/" rel="nofollow">dårligt link</a> og <meta name="robots" content="nofollow" />
Support til dette styres af muligheder: Scan hjemmeside | Webmaster filtre | Adlyd "a" tag "rel" nofollow og Scan hjemmeside | Webmaster filtre | Adlyd "meta" tag "robots" nofollow. - NoIndex:
<meta name="robots" content="noindex" />
Support til dette styres af muligheder: Scan hjemmeside | Webmaster filtre | Adlyd "meta" tag "robotter" noindex. - Meta omdirigering:
<meta http-equiv="refresh" content="0;url=https://example.com" />
Support til dette styres af muligheden: Scan hjemmeside | Crawler muligheder | Overvej 0 sekunders metaopdatering til omdirigering. - Javascript links og referencer:
<button onclick="myLinkClick()">eksempel</button>
Support til dette styres af muligheder:- Scan hjemmeside | Crawler muligheder | Prøv at søge i Javascript.
- Scan hjemmeside | Crawler muligheder | Prøv at søge i JSON.
Tip: Du kan desuden også vælge en AJAX- kompatibel crawler på Scan hjemmeside | Crawler motor.
Inkluder og ekskludér liste- og analysefiltre
Du kan læse mere i vores onlinehjælp til A1 Website Analyzer for at lære om analyse og outputfiltre.
Understøttelse af matchadfærd og jokertegn i Robots.txt
Matchadfærden i webstedscrawleren, der bruges af A1 Website Analyzer, ligner den for de fleste søgemaskiner.
Understøttelse af jokertegn i robots.txt -fil:
Webcrawleren i vores webstedsanalyseværktøj vil adlyde følgende brugeragent-id'er i robots.txt- filen:
Alle fundne disallow- instruktioner i robots.txt konverteres internt til både analyse- og outputfiltre i A1 Website Analyzer.
Understøttelse af jokertegn i robots.txt -fil:
- Standard : Match fra begyndelsen til filterets længde.
gre vil matche: greyfox, greenfox og green/fox. - Wildcard * : Match en hvilken som helst karakter, indtil en anden match bliver mulig.
gr*ræv vil matche: greyfox, grayfox, growl-fox og green/fox.
Tip: Jokertegnfiltre i robots.txt er ofte forkert konfigureret og en kilde til crawlproblemer.
Webcrawleren i vores webstedsanalyseværktøj vil adlyde følgende brugeragent-id'er i robots.txt- filen:
- Præcis match mod brugeragent valgt i: Generelle muligheder og værktøjer | Internet-crawler | Brugeragent-id.
- User-agent: A1 Website Analyzer, hvis produktnavnet er i den ovennævnte HTTP-brugeragent-streng.
- User-agent: miggibot, hvis crawlermotornavnet er i den ovennævnte HTTP-brugeragentstreng.
- Bruger-agent: *.
Alle fundne disallow- instruktioner i robots.txt konverteres internt til både analyse- og outputfiltre i A1 Website Analyzer.
Gennemgå resultater efter webstedsscanning
Se alle tilstandsflag for alle URL'er som registreret af crawleren - dette bruger indstillinger indstillet i webmasterfiltre, analysefiltre og outputfiltre.
Alternativt kan du bruge indstillingen Scan hjemmeside | Crawler muligheder | Brug specielle svarkoder til at få tilstande afspejlet som svarkoder.
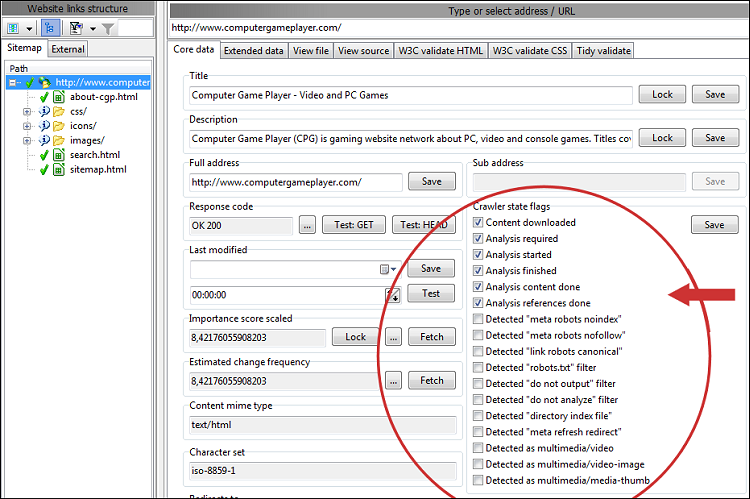
For detaljer om en specifik URL skal du vælge den og se alle oplysninger i Udvidede data | Detaljer, Udvidede data | Linket af og lignende:
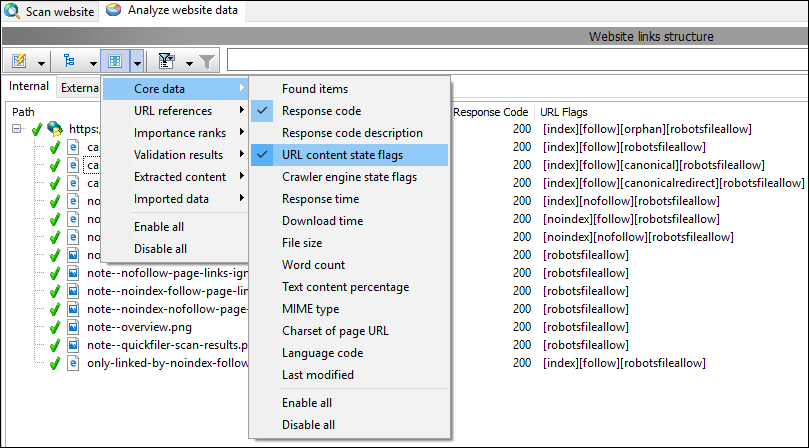
For at få et overblik over alle URL'er kan du skjule/vise de datakolonner, du ønsker, inklusive URL-indholdstilstandsflag :
Du kan også anvende et brugerdefineret filter efter scanning til kun at vise URL'er med en bestemt kombination af URL-tilstandsflag :

Alternativt kan du bruge indstillingen Scan hjemmeside | Crawler muligheder | Brug specielle svarkoder til at få tilstande afspejlet som svarkoder.
For detaljer om en specifik URL skal du vælge den og se alle oplysninger i Udvidede data | Detaljer, Udvidede data | Linket af og lignende:
For at få et overblik over alle URL'er kan du skjule/vise de datakolonner, du ønsker, inklusive URL-indholdstilstandsflag :
Du kan også anvende et brugerdefineret filter efter scanning til kun at vise URL'er med en bestemt kombination af URL-tilstandsflag :
