|
|

A1 Website Analyzer-Leitfaden zu Website- und SEO-Audits
Die Analyse der eigenen Website ist oft der erste Schritt bei jedem SEO-Audit. Hier finden Sie eine Schritt-für-Schritt-Anleitung.
Hinweis: Wir haben ein Video-Tutorial:
Übersicht über den A1 Website Analyzer
A1 Website Analyzer ist ein Tool zur Website- und Linkanalyse, das seit seiner ursprünglichen Veröffentlichung 1.0 im Jahr 2006 ständig weiterentwickelt wird.
Unsere Software verfügt über ein breites Arsenal an Tools. In diesem Artikel erfahren Sie, wie Sie die meisten davon für verschiedene Website- und SEO-Prüfungsaufgaben verwenden.
Sie können direkt zu bestimmten Teilen dieses Artikels springen:
Unsere Software verfügt über ein breites Arsenal an Tools. In diesem Artikel erfahren Sie, wie Sie die meisten davon für verschiedene Website- und SEO-Prüfungsaufgaben verwenden.
Sie können direkt zu bestimmten Teilen dieses Artikels springen:
- Erste Schritte – Website scannen
- Schnellberichte
- Sichtbare Datenspalten steuern
- Entdecken Sie interne Verlinkungsfehler
- Siehe Zeilennummern, Ankertexte und Follow/Nofollow für alle Links
- Sehen Sie, auf welche Bilder ohne „Alt“-Text verwiesen wird
- Verstehen Sie die interne Navigation und die Bedeutung von Links
- Alle Weiterleitungen anzeigen, Canonical, NoIndex und Ähnliches
- Suchen Sie nach doppeltem Inhalt
- Optimieren Sie Seiten für bessere SEO, einschließlich Titelgrößen
- Benutzerdefinierte Suchwebsite für Text und Code
- Sehen Sie sich die wichtigsten Schlüsselwörter in allen Website-Inhalten an
- Rechtschreibprüfung ganzer Websites
- Validieren Sie HTML und CSS aller Seiten
- Integration mit Online-Tools
- Crawlen Sie Websites mithilfe einer benutzerdefinierten Benutzeragenten-ID und eines Proxys
- Importieren Sie eine Liste von URLs und Protokolldateien zur weiteren Analyse
- Exportieren Sie Daten in HTML, CSV und Tools wie Excel
- Sehen Sie sich URLs mit AJAX-Fragmenten und -Inhalten an
- Windows, Mac und Linux
- Kostenlose Testversion, Preis, Upgrades und Installation
- Geschwister-Tools
Erste Schritte – Website scannen
Auf dem ersten Bildschirm, den Sie sehen, können Sie die Website-Adresse eingeben und den Crawl starten:
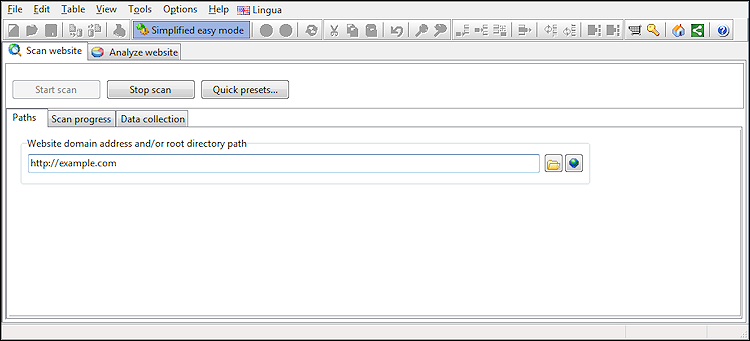
Standardmäßig sind die meisten erweiterten Optionen ausgeblendet und die Software verwendet ihre Standardeinstellungen.
Wenn Sie jedoch die Einstellungen ändern möchten, z. B. um mehr Daten zu sammeln oder die Crawl-Geschwindigkeit durch Erhöhung der Anzahl der maximalen Verbindungen zu erhöhen, können Sie alle Optionen sichtbar machen, indem Sie den vereinfachten einfachen Modus deaktivieren.
Im Screenshot unten haben wir die maximale Anzahl an Arbeitsthreads und gleichzeitigen Verbindungen angezeigt:
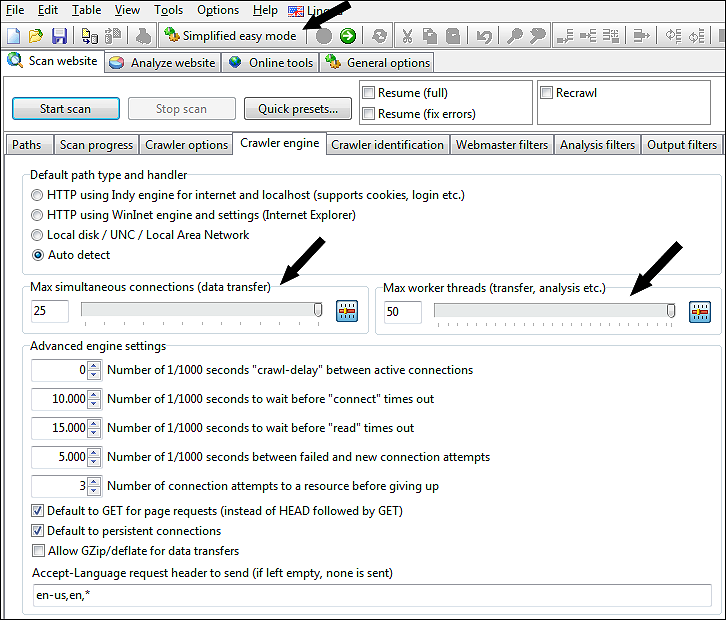
Standardmäßig sind die meisten erweiterten Optionen ausgeblendet und die Software verwendet ihre Standardeinstellungen.
Wenn Sie jedoch die Einstellungen ändern möchten, z. B. um mehr Daten zu sammeln oder die Crawl-Geschwindigkeit durch Erhöhung der Anzahl der maximalen Verbindungen zu erhöhen, können Sie alle Optionen sichtbar machen, indem Sie den vereinfachten einfachen Modus deaktivieren.
Im Screenshot unten haben wir die maximale Anzahl an Arbeitsthreads und gleichzeitigen Verbindungen angezeigt:
Schnellberichte
Dieses Dropdown-Menü zeigt eine Liste vordefinierter „Schnellberichte“, die nach dem Scannen einer Website verwendet werden können.
Diese vordefinierten Berichte konfigurieren die folgenden Optionen:
Sie können all dies auch manuell festlegen, um Ihre eigenen benutzerdefinierten Berichte zu erstellen. Dieser Leitfaden enthält beim Durchlesen verschiedene Beispiele hierfür.
Diese vordefinierten Berichte konfigurieren die folgenden Optionen:
- Welche Datenspalten sind sichtbar?
- Welche „Schnellfilteroptionen“ aktiv sind.
- Der „Schnellfiltertext“.
- Aktiviert die Schnellfilterung.
Sie können all dies auch manuell festlegen, um Ihre eigenen benutzerdefinierten Berichte zu erstellen. Dieser Leitfaden enthält beim Durchlesen verschiedene Beispiele hierfür.
Sichtbare Datenspalten steuern
Bevor wir die Website nach dem Scan weiter analysieren, müssen wir wissen, wie man Datenspalten ein- und ausschaltet, da es ein wenig überwältigend sein kann, sie alle auf einmal zu sehen.
Das Bild unten zeigt, wo Sie Spalten ein- und ausblenden können.
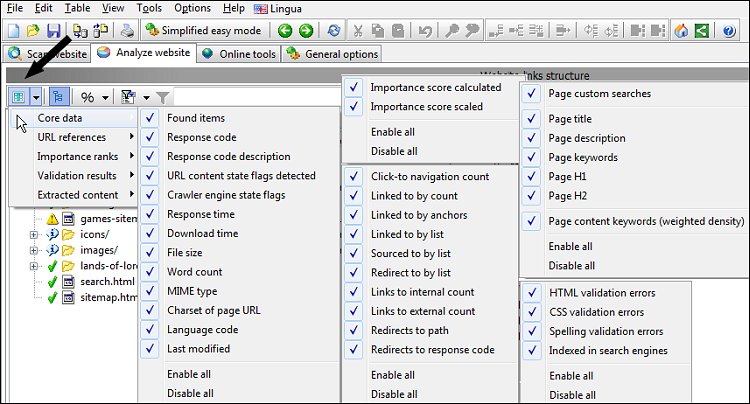
Möglicherweise möchten Sie auch die folgenden Optionen aktivieren oder deaktivieren:
Das Bild unten zeigt, wo Sie Spalten ein- und ausblenden können.
Möglicherweise möchten Sie auch die folgenden Optionen aktivieren oder deaktivieren:
- Ansicht | Erlauben Sie große URL-Listen in Datenspalten
- Anzeigen | Erlauben Sie relative Pfade innerhalb von URL-Listen in Datenspalten
- Anzeigen | Seiten-URLs nur innerhalb von URL-Listen in Datenspalten anzeigen
Entdecken Sie interne Verlinkungsfehler
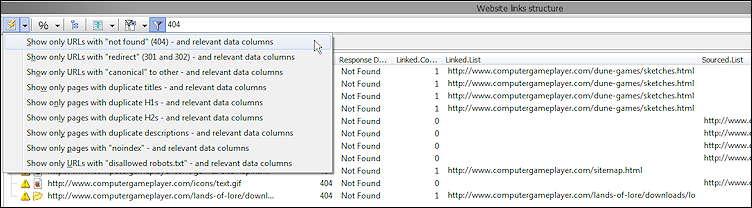
Bei der Suche nach Fehlern auf einer neuen Website ist es oft am schnellsten, Schnellfilter zu verwenden. In unserem folgenden Beispiel verwenden wir die Option „Nur URLs mit Filtertext in den Spalten „Antwortcode“ anzeigen“ in Kombination mit „404“ als Filtertext und klicken auf das Filtersymbol.
Auf diese Weise erhalten wir eine Liste von URLs mit dem Antwortcode 404, wie hier gezeigt:
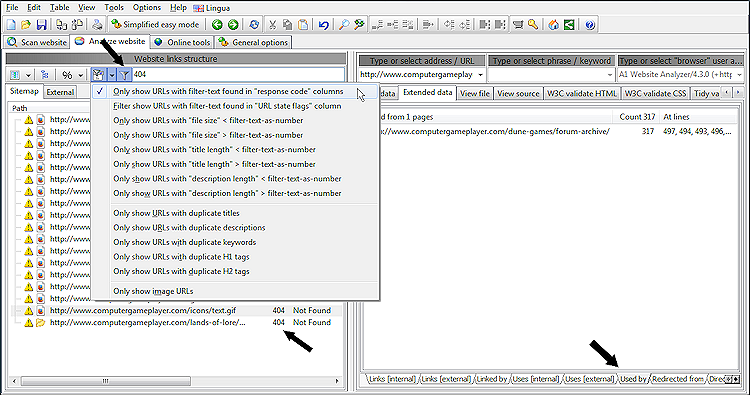
Wenn Sie auf der linken Seite eine 404-URL auswählen, können Sie auf der rechten Seite Details darüber sehen, wie und wo sie entdeckt wurde. Sie können alle URLs sehen, die auf die 404-URL verlinkt, verwendet (normalerweise das src- Attribut in HTML-Tags) oder umgeleitet haben.
Hinweis: Um auch externe Links prüfen zu lassen, aktivieren Sie diese Optionen:
Wenn Sie dies für Exporte nutzen möchten (später erklärt), können Sie auch Spalten aktivieren, die Ihnen die wichtigsten internen Backlinks und Ankertexte anzeigen.
Auf diese Weise erhalten wir eine Liste von URLs mit dem Antwortcode 404, wie hier gezeigt:
Wenn Sie auf der linken Seite eine 404-URL auswählen, können Sie auf der rechten Seite Details darüber sehen, wie und wo sie entdeckt wurde. Sie können alle URLs sehen, die auf die 404-URL verlinkt, verwendet (normalerweise das src- Attribut in HTML-Tags) oder umgeleitet haben.
Hinweis: Um auch externe Links prüfen zu lassen, aktivieren Sie diese Optionen:
- Website scannen | Datenerfassung | Option „Gefundene externe Links speichern“.
- Website scannen | Datenerfassung | Überprüfen Sie, ob externe URLs vorhanden sind (und analysieren Sie diese gegebenenfalls)
Wenn Sie dies für Exporte nutzen möchten (später erklärt), können Sie auch Spalten aktivieren, die Ihnen die wichtigsten internen Backlinks und Ankertexte anzeigen.
Siehe Zeilennummern, Ankertexte und Follow/Nofollow für alle Links
Für alle auf der gescannten Website gefundenen Links können folgende Informationen angezeigt werden:
Um sicherzustellen, dass Nofollow-Links beim Website-Crawling einbezogen werden, deaktivieren Sie die folgenden Optionen unter Website scannen | Webmaster-Filter:
- Die Zeilennummer in der Seitenquelle, in der sich der Link befindet.
- Der dem Link zugeordnete Ankertext.
- Ob der Link folgt oder nofollow ist
Um sicherzustellen, dass Nofollow-Links beim Website-Crawling einbezogen werden, deaktivieren Sie die folgenden Optionen unter Website scannen | Webmaster-Filter:
- Befolgen Sie das Nofollow-Meta-Tag „Roboter“.
- Befolgen Sie ein Tag „rel“ nofollow
Sehen Sie, auf welche Bilder ohne „Alt“-Text verwiesen wird
Bei der Verwendung von Bildern auf Websites ist es oft von Vorteil, Markup zu verwenden, das sie beschreibt, also das
Hierzu können Sie den integrierten Bericht „Nur Bilder anzeigen, bei denen bei einigen „verlinkt von“ oder „verwendet von““ Anker/„alt“ fehlen, verwenden. In diesem Bericht werden alle Bilder aufgelistet, die:
Dies wird erreicht durch:
Wenn Sie die Ergebnisse anzeigen, können Sie in erweiterten Details sehen, wo auf jedes Bild verwiesen wird, ohne dass einer der oben genannten Texttypen vorliegt. Im Screenshot unten untersuchen wir die verwendeten Daten, die aus Quellen wie
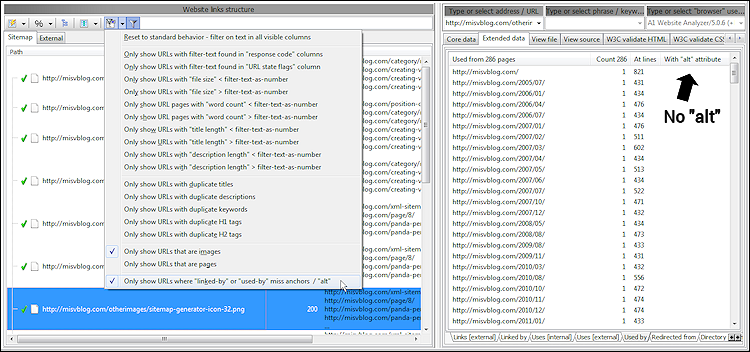
alt Attribut im <img> -HTML-Tag zu verwenden.Hierzu können Sie den integrierten Bericht „Nur Bilder anzeigen, bei denen bei einigen „verlinkt von“ oder „verwendet von““ Anker/„alt“ fehlen, verwenden. In diesem Bericht werden alle Bilder aufgelistet, die:
- Wird ohne Alternativtext verwendet
- Ohne Ankertext verlinkt.
Dies wird erreicht durch:
- Es werden nur relevante Datenspalten angezeigt.
- Filter aktivieren: Nur URLs anzeigen, die Bilder sind.
- Filter aktivieren: Nur URLs anzeigen, bei denen „linked-by“ oder „used-by“ Anker oder „alt“ fehlen.
Wenn Sie die Ergebnisse anzeigen, können Sie in erweiterten Details sehen, wo auf jedes Bild verwiesen wird, ohne dass einer der oben genannten Texttypen vorliegt. Im Screenshot unten untersuchen wir die verwendeten Daten, die aus Quellen wie
<img src="example.png" alt="example"> stammen. Verstehen Sie die interne Navigation und die Bedeutung von Links
Es kann sehr nützlich sein, zu verstehen, wie Ihre internen Website-Strukturen Suchmaschinen und Menschen dabei helfen, Ihre Inhalte zu finden.
Um zu sehen, wie viele Klicks ein Mensch benötigt, um von der Startseite aus zu einer bestimmten Seite zu gelangen, verwenden Sie die Datenspalte „Klicks zum Navigieren“.
Während die PageRank-Bildung größtenteils der Vergangenheit angehört, helfen Ihre internen Links und der weitergegebene Linkjuice den Suchmaschinen immer noch dabei, zu verstehen, welche Inhalte und Seiten Ihrer Meinung nach auf Ihrer Website am wichtigsten sind.
Unsere Software berechnet mithilfe der folgenden Schritte automatisch Wichtigkeitswerte für alle URLs:

Sie können den Algorithmus über die Menüoptionen beeinflussen:
Um Nofollow- Links einzubeziehen (die eine deutlich geringere Gewichtung erhalten als Follow- Links), deaktivieren Sie diese Optionen unter Website scannen | Webmaster-Filter:
Menschen
Um zu sehen, wie viele Klicks ein Mensch benötigt, um von der Startseite aus zu einer bestimmten Seite zu gelangen, verwenden Sie die Datenspalte „Klicks zum Navigieren“.
Suchmaschinen
Während die PageRank-Bildung größtenteils der Vergangenheit angehört, helfen Ihre internen Links und der weitergegebene Linkjuice den Suchmaschinen immer noch dabei, zu verstehen, welche Inhalte und Seiten Ihrer Meinung nach auf Ihrer Website am wichtigsten sind.
Unsere Software berechnet mithilfe der folgenden Schritte automatisch Wichtigkeitswerte für alle URLs:
- Links auf Seiten mit vielen eingehenden Links erhalten mehr Gewicht.
- Der Linkjuice, den eine Seite weitergeben kann, wird unter den ausgehenden Links geteilt.
- Die Werte werden auf eine logarithmische Basis umgerechnet und auf 0...10 skaliert.
Sie können den Algorithmus über die Menüoptionen beeinflussen:
- Werkzeuge | Option des Wichtigkeitsalgorithmus: Links „reduzieren“: Gewichtet wiederholte Links auf derselben Seite immer weniger. Weiter unten im Inhalt platzierte Links werden immer weniger gewichtet.
- Werkzeuge | Option des Wichtigkeitsalgorithmus: Links „noself“: Ignoriert Links, die auf dieselbe Seite verweisen, auf der sich der Link befindet.
Um Nofollow- Links einzubeziehen (die eine deutlich geringere Gewichtung erhalten als Follow- Links), deaktivieren Sie diese Optionen unter Website scannen | Webmaster-Filter:
- Befolgen Sie das Nofollow-Meta-Tag „Roboter“.
- Befolgen Sie ein Tag „rel“ nofollow
Alle Weiterleitungen anzeigen, Canonical, NoIndex und Ähnliches
Es ist möglich, Website-weite Informationen darüber anzuzeigen, welche URLs und Seiten:
Die oben genannten Daten werden hauptsächlich aus Meta-Tags, HTTP-Headern und Programmanalysen von URLs abgerufen.
Um alle Daten anzuzeigen, beenden Sie den Website-Scan und aktivieren Sie die Sichtbarkeit dieser Spalten:
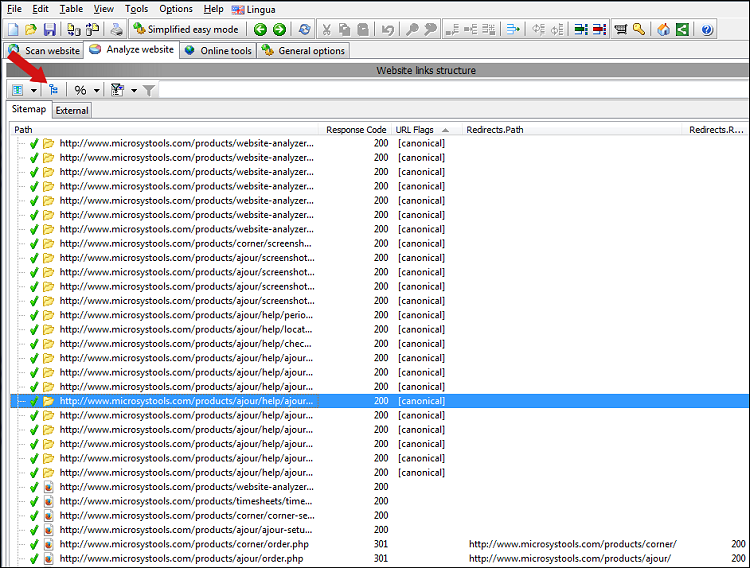
Beachten Sie, dass wir im obigen Screenshot die Baumansicht ausgeschaltet haben und stattdessen alle URLs im Listenansichtsmodus sehen.
So richten Sie einen umfassenden Filter ein, der alle Seiten anzeigt, die in irgendeiner Weise weiterleiten:
Dadurch werden die Filter so konfiguriert, dass URLs nur angezeigt werden, wenn sie die folgenden Bedingungen erfüllen:
- HTTP-Weiterleitungen.
- Meta-Aktualisierungsweiterleitungen.
- Ausgeschlossen durch robots.txt.
- Markierter kanonischer Verweis auf sich selbst, kanonischer Verweis auf eine andere URL als sich selbst, noindex oder nofollow, noarchive, nosnippet.
- Duplikate jeglicher Art, z. B. Index- oder fehlende Slash- Seiten-URLs.
- Und mehr..
Die oben genannten Daten werden hauptsächlich aus Meta-Tags, HTTP-Headern und Programmanalysen von URLs abgerufen.
Um alle Daten anzuzeigen, beenden Sie den Website-Scan und aktivieren Sie die Sichtbarkeit dieser Spalten:
- Kerndaten | Weg
- Kerndaten | Antwortcode
- Kerndaten | Statusflags für URL-Inhalte erkannt
- URL-Referenzen | Anzahl der Weiterleitungen
- URL-Referenzen | Leitet zum Pfad weiter
- URL-Referenzen | Leitet zum Antwortcode weiter
- URL-Referenzen | Weiterleitung zum Pfad (endgültig)
- URL-Referenzen | Weiterleitung zum Antwortcode (endgültig)
(Dies ist insbesondere hilfreich, um sicherzustellen, dass Ihre Weiterleitungsziele korrekt eingerichtet sind.)
Beachten Sie, dass wir im obigen Screenshot die Baumansicht ausgeschaltet haben und stattdessen alle URLs im Listenansichtsmodus sehen.
So richten Sie einen umfassenden Filter ein, der alle Seiten anzeigt, die in irgendeiner Weise weiterleiten:
- Aktivieren Sie zunächst die Optionen:
- Anzeigen | Datenfilteroptionen | Es werden nur URLs angezeigt, die alle in der Spalte „URL-Statusflags“ gefundenen [Filtertexte] enthalten
- Anzeigen | Datenfilteroptionen | Es werden nur URLs angezeigt, deren Filtertextnummer in der Spalte „Antwortcode“ enthalten ist
- Ansicht | Datenfilteroptionen | Zeigen Sie nur URLs an, bei denen es sich um Seiten handelt
- Danach verwenden Sie Folgendes als Schnellfiltertext:
[httpredirect|canonicalredirect|metarefreshredirect] -[noindex] 200 301 302 307
Dadurch werden die Filter so konfiguriert, dass URLs nur angezeigt werden, wenn sie die folgenden Bedingungen erfüllen:
- Die URL muss eine Seite sein und darf beispielsweise kein Bild sein.
- Die URL muss entweder eine HTTP-Umleitung oder eine Meta-Aktualisierung oder einen kanonischen Verweis auf eine andere Seite ermöglichen.
- Die URL darf keine Noindex-Anweisung enthalten.
- Der URL-HTTP-Antwortcode muss entweder 200, 301, 302 oder 307 sein.
Suchen Sie nach doppeltem Inhalt
Doppelte Seitentitel, Kopfzeilen usw.
Im Allgemeinen ist es keine gute Idee, wenn mehrere Seiten dieselben doppelten Titel, Überschriften und Beschreibungen haben. Um solche Seiten zu finden, können Sie nach Abschluss des ersten Website-Crawlings die Schnellfilterfunktion verwenden.
Im Screenshot unten haben wir unseren Schnellfilter darauf beschränkt, nur Seiten mit doppelten Titeln anzuzeigen, die in einer ihrer Datenspalten auch die Zeichenfolge „das Spiel“ enthalten.
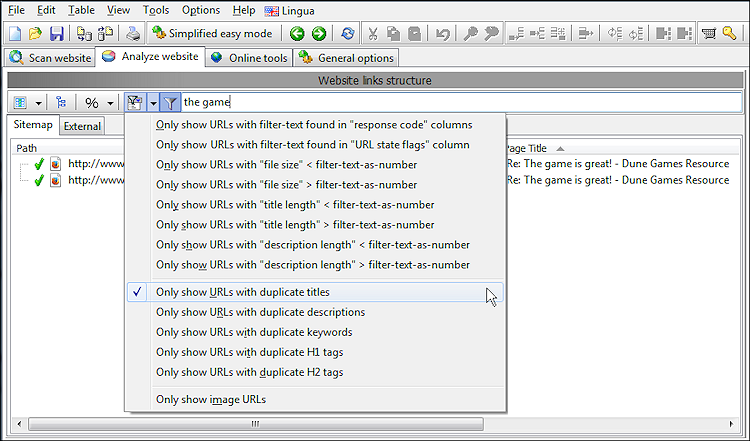
Doppelter Seiteninhalt
Einige Tools können eine einfache MD5-Hash- Prüfung aller Seiten einer Website durchführen. Dadurch erfahren Sie jedoch nur, dass die Seiten zu 100 % identisch sind, was bei den meisten Websites nicht sehr wahrscheinlich der Fall ist.
Stattdessen kann A1 Website Analyzer Seiten mit ähnlichem Inhalt sortieren und gruppieren. Darüber hinaus können Sie eine visuelle Darstellung der hervorstechendsten Seitenelemente sehen. Zusammen ergibt dies eine nützliche Kombination zum Auffinden von Seiten, die möglicherweise doppelten Inhalt haben. Um dies zu verwenden:
- Aktivieren Sie die Option Website scannen | Datenerfassung | Führen Sie eine Keyword-Dichteanalyse aller Seiten durch, bevor Sie die Website scannen.
- Aktivieren Sie die Sichtbarkeit der Datenspalte Seiteninhaltsähnlichkeit.

Bevor Sie einen Site-Scan starten, können Sie die Genauigkeit erhöhen, indem Sie unter Website analysieren | die folgenden Optionen festlegen Keyword-Analyse.
- Stellen Sie „Stoppwörter auswählen“ entsprechend der Hauptsprache Ihrer Website ein oder wählen Sie „Automatisch “, wenn mehrere Sprachen verwendet werden.
- Legen Sie die Option „Verwendung von Stoppwörtern“ auf „Aus Inhalt entfernt“ fest.
- Standortanalyse festlegen | Maximale Wörter pro Phrase: 2.
- Standortanalyse festlegen | Max. Ergebnisse pro Zähltyp auf einen höheren Wert als den Standardwert festlegen, z. B. 40.
Hinweis: Wenn Sie auf Ihrer Website mehrere Sprachen verwenden, lesen Sie hier, wie die Seitensprachenerkennung in A1 Website Analyzer funktioniert.
Doppelte URLs
Viele Websites enthalten Seiten, auf die über mehrere eindeutige URLs zugegriffen werden kann. Solche URLs sollten Suchmaschinen umleiten oder auf andere Weise auf die primäre Quelle verweisen. Wenn Sie die Sichtbarkeit der Crawler-Flags der Datenspalte aktivieren, können Sie alle Seiten-URLs sehen, die:
- Leiten Sie mithilfe von Canonical, HTTP-Redirect oder Meta-Refresh explizit um oder verweisen Sie auf andere URLs.
- Sind anderen URLs ähnlich, z. B. example/dir/, example/dir und example/dir/index.html. Für diese werden die primären und doppelten URLs basierend auf HTTP-Antwortcodes und interner Verlinkung berechnet und angezeigt.
Optimieren Sie Seiten für bessere SEO, einschließlich Titelgrößen
Für diejenigen, die On-Page-SEO für alle Seiten durchführen möchten, gibt es einen integrierten Bericht, der Ihnen die wichtigsten Datenspalten anzeigt, darunter:
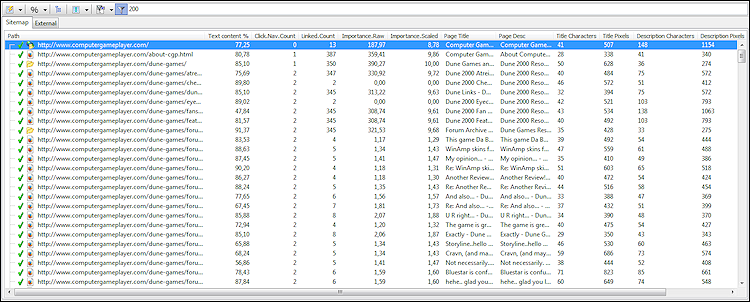
Hinweis: Es ist möglich, die Daten auf verschiedene Weise zu filtern – z. B. so, dass Sie nur Seiten sehen, deren Titel zu lang sind, um in den Suchergebnissen angezeigt zu werden.
- Wortanzahl im Seiteninhalt.
- Text versus Code-Prozentsatz.
- Länge des Titels und der Beschreibung in Zeichen.
- Titel- und Beschreibungslänge in Pixel.
- Interne Verlinkung und Seitenbewertungen.
- Klicks auf Links, die erforderlich sind, um eine Seite vom Domänenstamm aus zu erreichen.
Hinweis: Es ist möglich, die Daten auf verschiedene Weise zu filtern – z. B. so, dass Sie nur Seiten sehen, deren Titel zu lang sind, um in den Suchergebnissen angezeigt zu werden.
Benutzerdefinierte Suchwebsite für Text und Code
Bevor Sie mit dem ersten Website-Scan beginnen, können Sie verschiedene Text-/Codemuster konfigurieren, nach denen Sie suchen möchten, während die Seiten analysiert und gecrawlt werden.
Sie können dies unter Website scannen | konfigurieren Datenerfassung, und es ist möglich, sowohl vordefinierte Muster zu verwenden als auch eigene zu erstellen. Dies kann sehr nützlich sein, um zu sehen, ob beispielsweise Google Analytics auf allen Seiten korrekt installiert wurde.
Beachten Sie, dass wir jedes unserer Suchmuster benennen müssen, damit wir sie später unterscheiden können.
In unserem Screenshot haben wir ein Muster namens ga_new, das mithilfe eines regulären Ausdrucks nach Google Analytic sucht. (Wenn Sie sich mit regulären Ausdrücken nicht auskennen, reicht es oft auch aus, einfach einen Ausschnitt des gesuchten Textes oder Codes zu schreiben.)
Stellen Sie beim Hinzufügen und Entfernen von Mustern sicher, dass Sie diese mithilfe der Schaltflächen [+] und [-] zur Dropdown-Liste hinzugefügt bzw. daraus entfernt haben.
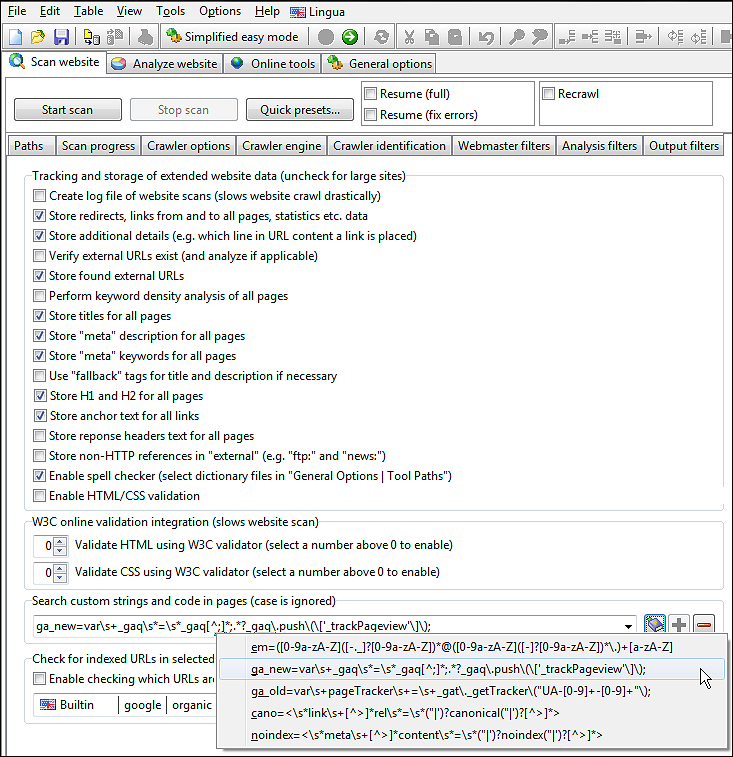
Nachdem der Website-Scan abgeschlossen ist, können Sie sehen, wie oft jedes hinzugefügte Suchmuster auf allen Seiten gefunden wurde.
Sie können dies unter Website scannen | konfigurieren Datenerfassung, und es ist möglich, sowohl vordefinierte Muster zu verwenden als auch eigene zu erstellen. Dies kann sehr nützlich sein, um zu sehen, ob beispielsweise Google Analytics auf allen Seiten korrekt installiert wurde.
Beachten Sie, dass wir jedes unserer Suchmuster benennen müssen, damit wir sie später unterscheiden können.
In unserem Screenshot haben wir ein Muster namens ga_new, das mithilfe eines regulären Ausdrucks nach Google Analytic sucht. (Wenn Sie sich mit regulären Ausdrücken nicht auskennen, reicht es oft auch aus, einfach einen Ausschnitt des gesuchten Textes oder Codes zu schreiben.)
Stellen Sie beim Hinzufügen und Entfernen von Mustern sicher, dass Sie diese mithilfe der Schaltflächen [+] und [-] zur Dropdown-Liste hinzugefügt bzw. daraus entfernt haben.
Nachdem der Website-Scan abgeschlossen ist, können Sie sehen, wie oft jedes hinzugefügte Suchmuster auf allen Seiten gefunden wurde.
Sehen Sie sich die wichtigsten Schlüsselwörter in allen Website-Inhalten an
Es ist möglich, beim Site-Crawling die Top-Wörter aller Seiten zu extrahieren.
Aktivieren Sie dazu die Option Website scannen | Datenerfassung | Führen Sie eine Keyword-Dichteanalyse aller Seiten durch.
Der Algorithmus zur Berechnung der Keyword-Scores berücksichtigt folgende Dinge:
Die angezeigten Ergebnisse sind so formatiert, dass sie für Menschen lesbar sind, sich aber auch mit benutzerdefinierten Skripten und Tools problemlos weiter analysieren lassen. (Das ist nützlich, wenn Sie die Daten exportieren möchten.)
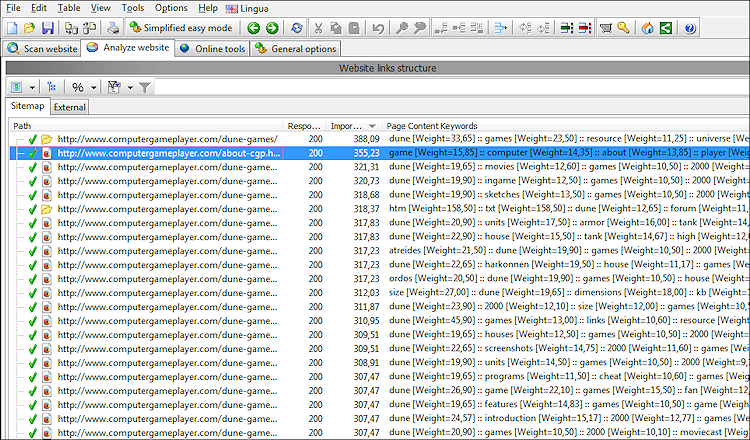
Wenn Sie lieber eine detaillierte Aufschlüsselung der Schlüsselwörter auf einzelnen Seiten erhalten möchten, können Sie auch Folgendes erhalten:

Hier können Sie auch konfigurieren, wie Keyword-Scores berechnet werden. Weitere Informationen hierzu finden Sie auf der Hilfeseite von A1 Keyword Research zur On-Page-Analyse von Keywords.
Aktivieren Sie dazu die Option Website scannen | Datenerfassung | Führen Sie eine Keyword-Dichteanalyse aller Seiten durch.
Der Algorithmus zur Berechnung der Keyword-Scores berücksichtigt folgende Dinge:
- Versucht, Sprache zu erkennen und die richtige Liste von Stoppwörtern anzuwenden.
- Die Keyword-Dichte im gesamten Seitentext.
- Text in wichtigen HTML-Elementen ist wichtiger als normaler Text.
Die angezeigten Ergebnisse sind so formatiert, dass sie für Menschen lesbar sind, sich aber auch mit benutzerdefinierten Skripten und Tools problemlos weiter analysieren lassen. (Das ist nützlich, wenn Sie die Daten exportieren möchten.)
Wenn Sie lieber eine detaillierte Aufschlüsselung der Schlüsselwörter auf einzelnen Seiten erhalten möchten, können Sie auch Folgendes erhalten:
Hier können Sie auch konfigurieren, wie Keyword-Scores berechnet werden. Weitere Informationen hierzu finden Sie auf der Hilfeseite von A1 Keyword Research zur On-Page-Analyse von Keywords.
Rechtschreibprüfung ganzer Websites
Wenn Sie in Website scannen | Wenn Sie sich bei der Datenerfassung für eine Rechtschreibprüfung entscheiden, können Sie nach Abschluss des Crawls auch die Anzahl der Rechtschreibfehler für alle Seiten sehen.
Um die spezifischen Fehler anzuzeigen, können Sie den Quellcode der folgenden Dateien anzeigen, indem Sie auf Extras | klicken Dokument zur Rechtschreibprüfung.

Wie Sie sehen, können die Wörterbuchdateien nicht alles enthalten. Daher ist es oft von Vorteil, einen vorläufigen Scan durchzuführen, bei dem Sie häufig verwendete Wörter, die für Ihre Website-Nische spezifisch sind, zum Wörterbuch hinzufügen.

Um die spezifischen Fehler anzuzeigen, können Sie den Quellcode der folgenden Dateien anzeigen, indem Sie auf Extras | klicken Dokument zur Rechtschreibprüfung.
Wie Sie sehen, können die Wörterbuchdateien nicht alles enthalten. Daher ist es oft von Vorteil, einen vorläufigen Scan durchzuführen, bei dem Sie häufig verwendete Wörter, die für Ihre Website-Nische spezifisch sind, zum Wörterbuch hinzufügen.
Validieren Sie HTML und CSS aller Seiten
A1 Website Analyzer kann mehrere verschiedene HTML/CSS-Seitenprüfer verwenden, darunter W3C/HTML, W3C/CSS, Tidy/HTML, CSE/HTML und CSE/CSS.
Da die HTML-/CSS-Validierung das Crawlen von Websites verlangsamen kann, sind diese Optionen standardmäßig deaktiviert.
Liste der für die HTML/CSS-Validierung verwendeten Optionen:
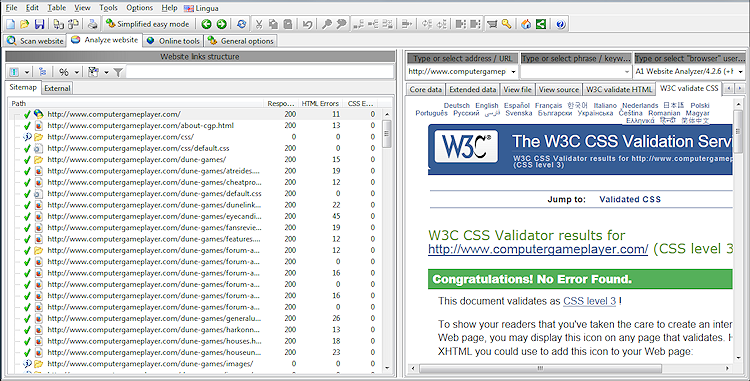
Wenn Sie einen Website-Scan mit aktivierter HTML-/CSS-Validierung abgeschlossen haben, sieht das Ergebnis etwa so aus:
Da die HTML-/CSS-Validierung das Crawlen von Websites verlangsamen kann, sind diese Optionen standardmäßig deaktiviert.
Liste der für die HTML/CSS-Validierung verwendeten Optionen:
- Website scannen | Datenerfassung | Aktivieren Sie die HTML/CSS-Validierung
- Allgemeine Optionen und Tools | Werkzeugwege | TIDY-Ausführungspfad
- Allgemeine Optionen und Tools | Werkzeugwege | Ausführbarer Pfad der CSE HTML Validator-Befehlszeile
- Website scannen | Datenerfassung | Validieren Sie HTML mit dem W3C HTML Validator
- Website scannen | Datenerfassung | Validieren Sie CSS mit dem W3C CSS Validator
Wenn Sie einen Website-Scan mit aktivierter HTML-/CSS-Validierung abgeschlossen haben, sieht das Ergebnis etwa so aus:
Integration mit Online-Tools
Um den täglichen Arbeitsablauf zu erleichtern, verfügt die Software über eine separate Registerkarte mit verschiedenen Online-Tools von Drittanbietern.
Abhängig von der ausgewählten URL und den verfügbaren Daten können Sie eines der Online-Tools in der Dropdown-Liste auswählen und die richtige URL einschließlich Abfrageparametern wird automatisch in einem eingebetteten Browser geöffnet.
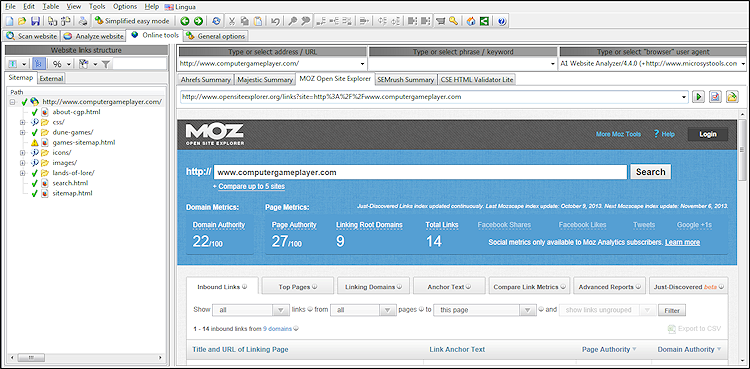
Abhängig von der ausgewählten URL und den verfügbaren Daten können Sie eines der Online-Tools in der Dropdown-Liste auswählen und die richtige URL einschließlich Abfrageparametern wird automatisch in einem eingebetteten Browser geöffnet.
Crawlen Sie Websites mithilfe einer benutzerdefinierten Benutzeragenten-ID und eines Proxys
Manchmal kann es nützlich sein, die beim Crawlen von Websites verwendete Benutzeragenten-ID und IP-Adresse zu verbergen.
Mögliche Gründe können sein, wenn eine Website:
Sie können diese Dinge unter Allgemeine Optionen und Tools | konfigurieren Internet-Crawler.
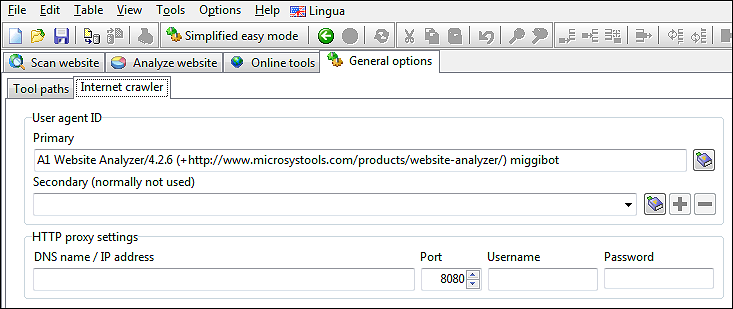
Mögliche Gründe können sein, wenn eine Website:
- Gibt für Crawler andere Inhalte zurück als für Menschen, z. B. Website-Cloaking.
- Verwendet IP-Adressbereiche, um das Land zu erkennen und anschließend auf eine andere Seite/Site umzuleiten.
Sie können diese Dinge unter Allgemeine Optionen und Tools | konfigurieren Internet-Crawler.
Importieren Sie Daten von Drittanbieterdiensten
Sie können URLs und erweiterte Daten von Drittanbietern über das Menü Datei | importieren Importieren Sie URLs aus text/log/csv.
Je nachdem, was Sie importieren, werden alle URLs entweder auf den internen oder externen Registerkarten platziert.
Der Import kann sowohl zum Hinzufügen weiterer Informationen zu vorhandenen Crawling-Daten als auch zum Seeding neuer Crawls verwendet werden.
Es werden zusätzliche Daten importiert, wenn die Quelldaten stammen aus:
Um einen Website-Crawl von den importierten URLs aus zu starten, können Sie:
Um die importierten URLs im externen Tab zu crawlen, aktivieren Sie die folgenden Optionen:
Je nachdem, was Sie importieren, werden alle URLs entweder auf den internen oder externen Registerkarten platziert.
Der Import kann sowohl zum Hinzufügen weiterer Informationen zu vorhandenen Crawling-Daten als auch zum Seeding neuer Crawls verwendet werden.
Es werden zusätzliche Daten importiert, wenn die Quelldaten stammen aus:
- Apache- Serverprotokolle:
- Welche Seiten wurden von GoogleBot aufgerufen? Dies wird von [googlebot] in der Datenspalte URL Flags angezeigt.
- Welche URLs, die nicht intern verlinkt oder verwendet werden. Dies wird durch [orphan] in der Datenspalte URL Flags angezeigt.
- CSV-Exporte der Google Search Console:
- Welche Seiten werden von Google indiziert? Dies wird von [googleindexed] in der Datenspalte URL Flags angezeigt.
- Klicks für jede URL in den Google-Suchergebnissen – diese werden in der Datenspalte „Klicks“ angezeigt.
- Impressionen jeder URL in den Google-Suchergebnissen – diese werden in der Datenspalte Impressions angezeigt.
- Majestic CSV-Exporte:
- Link-Score aller URLs – dieser wird in der Datenspalte Backlinks-Score angezeigt. Sofern verfügbar, werden die Daten verwendet, um die Berechnungen hinter den Datenspalten „Wichtigkeitswert berechnet“ und „Wichtigkeitswert skaliert“ weiter zu verbessern.
Um einen Website-Crawl von den importierten URLs aus zu starten, können Sie:
- Aktivieren Sie die Option Website scannen | Erneut crawlen.
- Aktivieren Sie die Option Website scannen | Erneutes Crawlen (nur aufgeführt) – Dadurch wird vermieden, dass neue URLs in die Analysewarteschlange und die Ergebnisausgabe aufgenommen werden.
Um die importierten URLs im externen Tab zu crawlen, aktivieren Sie die folgenden Optionen:
- Website scannen | Datenerfassung | Option „Gefundene externe Links speichern“.
- Website scannen | Datenerfassung | Überprüfen Sie, ob externe URLs vorhanden sind (und analysieren Sie diese gegebenenfalls)
Exportieren Sie Daten in HTML, CSV und Tools wie Excel
Im Allgemeinen können Sie den Inhalt eines beliebigen Datensteuerelements exportieren, indem Sie darauf fokussieren/anklicken und anschließend die Datei | verwenden Ausgewählte Daten in Datei exportieren... oder Datei | Ausgewählte Daten in die Zwischenablage exportieren... Menüpunkte.
Standardmäßig werden Daten als Standard-CSV-Dateien exportiert. Falls das Programm, in das Sie die CSV-Dateien importieren möchten, jedoch besondere Anforderungen hat oder Sie beispielsweise auch Spaltenüberschriften aufgelistet haben möchten, können Sie die Einstellungen anpassen Menü Datei | Export- und Importoptionen.
Die Daten, die Sie normalerweise exportieren, finden Sie in der Hauptansicht. Hier können Sie benutzerdefinierte Exporte und Berichte erstellen, die genau die Informationen enthalten, die Sie benötigen. Wählen Sie einfach aus, welche Spalten sichtbar sind, aktivieren Sie vor dem Exportieren die gewünschten Schnellfilter (z. B. nur 404 nicht gefundene Fehler, doppelte Titel oder ähnliches).
Alternativ können Sie auch die integrierten Berichtsschaltflächen verwenden, die verschiedene Konfigurationsvoreinstellungen enthalten:
Hinweis: Sie können viele weitere Datenansichten erstellen, wenn Sie lernen, wie Sie Filter und sichtbare Spalten konfigurieren.
Standardmäßig werden Daten als Standard-CSV-Dateien exportiert. Falls das Programm, in das Sie die CSV-Dateien importieren möchten, jedoch besondere Anforderungen hat oder Sie beispielsweise auch Spaltenüberschriften aufgelistet haben möchten, können Sie die Einstellungen anpassen Menü Datei | Export- und Importoptionen.
Die Daten, die Sie normalerweise exportieren, finden Sie in der Hauptansicht. Hier können Sie benutzerdefinierte Exporte und Berichte erstellen, die genau die Informationen enthalten, die Sie benötigen. Wählen Sie einfach aus, welche Spalten sichtbar sind, aktivieren Sie vor dem Exportieren die gewünschten Schnellfilter (z. B. nur 404 nicht gefundene Fehler, doppelte Titel oder ähnliches).
Alternativ können Sie auch die integrierten Berichtsschaltflächen verwenden, die verschiedene Konfigurationsvoreinstellungen enthalten:
Hinweis: Sie können viele weitere Datenansichten erstellen, wenn Sie lernen, wie Sie Filter und sichtbare Spalten konfigurieren.
Sehen Sie sich URLs mit AJAX-Fragmenten und -Inhalten an
Kurze Erklärung von Fragmenten in URLs:
Vor dem Website-Scan:
Nach dem Website-Scan:

- Page-relative-fragments: Relative Links innerhalb einer Seite:
http://example.com/somepage#relative-page-link - AJAX-Fragmente: clientseitiges Javascript, das serverseitigen Code abfragt und Inhalte im Browser ersetzt:
http://example.com/somepage#lookup-replace-data
http://example.com/somepage#!lookup-replace-data - AJAX-fragments-Google-initiative: Teil der Google- Initiative „Making AJAX Applications Crawlable “:
http://example.com/somepage#!lookup-replace-data
Diese Lösung wurde inzwischen von Google selbst abgelehnt.
Vor dem Website-Scan:
- Hash- Fragmente
#werden bei Verwendung der Standardeinstellungen entfernt. Um dies zu ändern, deaktivieren Sie Folgendes:- In Website scannen | Crawler-Optionen | Ausschnitt „#“ in internen Links
- In Website scannen | Crawler-Optionen | Ausschnitt „#“ in externen Links
- Hashbang- Fragmente
#!bleiben stets erhalten und enthalten. - Wenn Sie AJAX-Inhalte analysieren möchten, die unmittelbar nach dem ersten Laden der Seite abgerufen werden:
- Windows: In Website scannen | Crawler-Engine wählt HTTP mit WinInet + IE-Browser aus
- Windows: In Website scannen | Crawler-Engine wählt HTTP mithilfe der Mac OS API + Browser aus
Nach dem Website-Scan:
- Um alle URLs mit
#einfach anzuzeigen, verwenden Sie den Schnellfilter. - Wenn Sie
#!Für AJAX-URLs können Sie von Folgendem profitieren:- Sichtbarkeit der Datenspalte Kerndaten | aktivieren URL-Inhaltsstatusflags erkannt.
- Sie können nach den Flags „[ajaxbyfragmentmeta]“ und „[ajaxbyfragmenturl]“ filtern oder suchen.
Windows, Mac und Linux
A1 Website Analyzer ist als native Software für Windows und Mac verfügbar.
Das Windows-Installationsprogramm wählt abhängig von der verwendeten Windows-Version automatisch die beste verfügbare Binärdatei aus, z. B. 32 Bit oder 64 Bit.
Unter Linux können Sie stattdessen häufig Virtualisierungs- und Emulationslösungen wie WINE verwenden.
Das Windows-Installationsprogramm wählt abhängig von der verwendeten Windows-Version automatisch die beste verfügbare Binärdatei aus, z. B. 32 Bit oder 64 Bit.
Unter Linux können Sie stattdessen häufig Virtualisierungs- und Emulationslösungen wie WINE verwenden.
Kostenlose Testversion, Preis, Upgrades und Installation
Um die kostenlose 30-Tage-Testversion auszuprobieren, laden Sie sie einfach herunter und installieren Sie sie. Es gibt keine künstlichen Seiten- oder URL-Beschränkungen.
Wenn Sie A1 Website Analyzer kaufen, beträgt der Preis 69 USD und beinhaltet:
Je nachdem, wann Sie kaufen, ist möglicherweise auch der Zugriff auf die 12.x-Serie enthalten, wenn die erste 12.x-Version innerhalb eines Jahres nach Ihrem 11.x-Kauf veröffentlicht wird. Wenn nicht, gibt es einen ermäßigten Upgrade-Preis.
Hinweis: Wenn Sie beispielsweise bereits Version 11.0.0 installiert haben, können Sie auf die neueste Version 11.0.0 aktualisieren, indem Sie diese einfach herunterladen und installieren.
Wenn Sie A1 Website Analyzer kaufen, beträgt der Preis 69 USD und beinhaltet:
- Alle Releases der Versionsreihe 11.x.
- Es gibt keinen monatlichen oder jährlichen Abonnementpreis.
- Sie können die Software so lange nutzen, wie Sie möchten.
Je nachdem, wann Sie kaufen, ist möglicherweise auch der Zugriff auf die 12.x-Serie enthalten, wenn die erste 12.x-Version innerhalb eines Jahres nach Ihrem 11.x-Kauf veröffentlicht wird. Wenn nicht, gibt es einen ermäßigten Upgrade-Preis.
Hinweis: Wenn Sie beispielsweise bereits Version 11.0.0 installiert haben, können Sie auf die neueste Version 11.0.0 aktualisieren, indem Sie diese einfach herunterladen und installieren.
Geschwister-Tools
Wenn dem A1 Website Analyzer eine Funktion fehlt, können Sie versuchen, die Schwestertools zu überprüfen. Einige gemeinsame Merkmale aller A1 -Tools sind:
Während A1 Website Analyzer keine Sitemaps erstellt, wird dies bei seinem Schwestertool A1 Sitemap Generator der Fall sein. Dazu gehören XML-Sitemaps, Video-Sitemaps, Bild-Sitemaps, HTML-Sitemaps und einige andere Formate.
- Ähnliche Benutzeroberfläche.
- Kann Projektdateien und Daten teilen.
- Cross-Sale-Rabatte sind während des Bestellvorgangs verfügbar.
Sitemaps
Während A1 Website Analyzer keine Sitemaps erstellt, wird dies bei seinem Schwestertool A1 Sitemap Generator der Fall sein. Dazu gehören XML-Sitemaps, Video-Sitemaps, Bild-Sitemaps, HTML-Sitemaps und einige andere Formate.
