|
|

Analyze Internal Linking with A1 Website Analyzer
If you want to see from where a page or file is linked/used/redirected to by, you can do so with our website analyzer software.
Note: We have a video tutorial:

Analysing Links and Redirects
You need to scan your website before
you can view all the URLs found in the website!
If you experience website crawl problems, e.g. get fewer than expected found URLs during website scan, see our article about
solving website crawling problems.
If you are interested in viewing how pages interlink, A1 Website Analyzer gives you complete access to view linked to by, redirected to by, used by and lots of other related data. This is useful for finding broken links that give e.g. response code 404 Not Found or response code 301 Moved Permanently errors. You can switch between the information shown in Extended data using the tabs at the bottom.
Note: If the root directory or start search paths themselves give an error response, please remember that these paths were supplied to the website analyzer program in its project settings. Therefore it may be that there are no broken links or similar pointing to these URLs.

What A1 Website Analyzer interpretes as links increases with options like:
Explanations of what the different tabs under Extended data mean:
You can change how you view URLs found in during the website scan. Switch between tree outline and flat list. This is especially useful when sorting URLs based on HTTP response code to find all broken links. You can sort the URLs listed by clicking any of the data columns, e.g. R.Code which is short for response code.
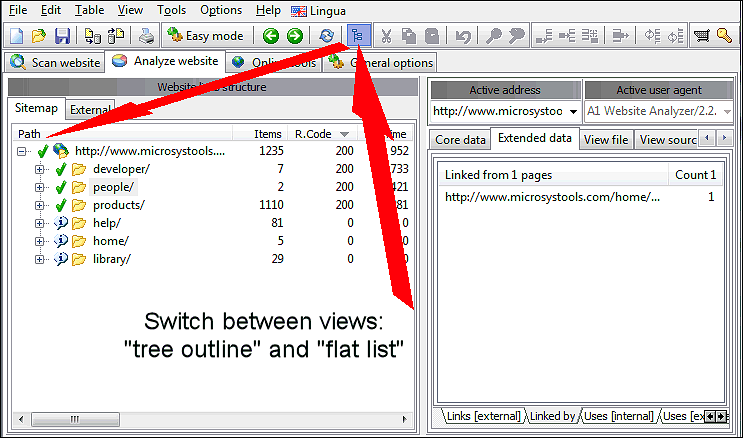
Broken links can often be found by looking for URLs that return response code 404 : Not Found and 301 : Moved Permanently. Just check their Linked by, Used by and Redirected by information.
You should also be aware how nofollow, noindex and robots.txt can affect website crawling. If you want A1 Website Analyzer to show all URLs found including those marked noindex, you can do so through options:
If you are interested in viewing how pages interlink, A1 Website Analyzer gives you complete access to view linked to by, redirected to by, used by and lots of other related data. This is useful for finding broken links that give e.g. response code 404 Not Found or response code 301 Moved Permanently errors. You can switch between the information shown in Extended data using the tabs at the bottom.
Note: If the root directory or start search paths themselves give an error response, please remember that these paths were supplied to the website analyzer program in its project settings. Therefore it may be that there are no broken links or similar pointing to these URLs.
What A1 Website Analyzer interpretes as links increases with options like:
- Website scan | Crawler options | Search all link tag types.
- Website scan | Crawler options | Consider <iframe> tags for links.
- Website scan | Crawler options | try search inside Javascript and CSS.
Explanations of what the different tabs under Extended data mean:
- Links [internal]: Links from the selected URL to other URLs on the same domain.
- Links [external]: Links from the selected URL to other URLs on another domain.
- Linked by: From where the selected URL is linked internally.
- Uses [internal]: Resources (e.g. images) on the same domain the selected URL uses.
- Uses [external]: Resources (e.g. images) from another domain the selected URL uses.
- Used by: From where the selected URL (e.g. an image) is used internally.
- Redirected by: Which internal URLs redirects to the selected URL.
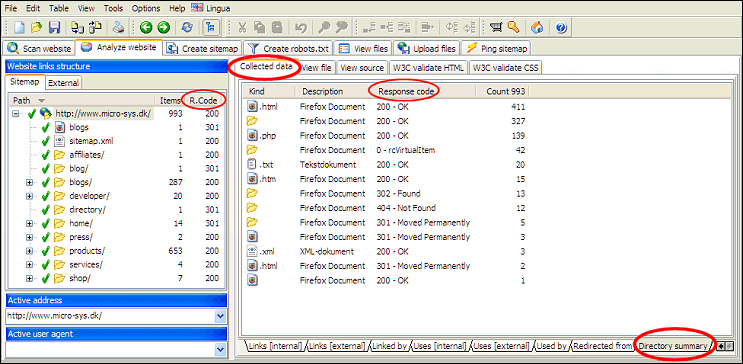
- Directory summary: Overview of the types of URLs located under the selected URL.
You can change how you view URLs found in during the website scan. Switch between tree outline and flat list. This is especially useful when sorting URLs based on HTTP response code to find all broken links. You can sort the URLs listed by clicking any of the data columns, e.g. R.Code which is short for response code.
Broken links can often be found by looking for URLs that return response code 404 : Not Found and 301 : Moved Permanently. Just check their Linked by, Used by and Redirected by information.
You should also be aware how nofollow, noindex and robots.txt can affect website crawling. If you want A1 Website Analyzer to show all URLs found including those marked noindex, you can do so through options:
- For website scan results: Uncheck: Scan website | Webmaster filters | After website scan stops: Remove URLs with noindex/disallow.
Directory and Pages Summary
You can always quickly select and view summary information for directories in a website:
Advanced Link and Redirect Issues
-
Have you enabled option Use special response codes for when page URLs use canonical,
but are confused about URLs with response code
-9 : RedirectIndexFileDirRoot
or
-11 : MetaRefreshRedirect
in scan results? If so, be sure to read about
duplicate URLs
and how to enable/disable automatic detection of them.
-
Do you have directories with response code 0 : VirtualItem in scan results?
Those URLs have not been analyzed because they are not directly linked from anywhere.
You can force website analyzer to include such URLs in website scans by enabling
Scan website | Crawler options | Always scan directories that contain linked URLs.

Internal Links and "Uses" Only Sometimes Show Or Are Wrong
Some websites generate different HTML code and links at random or
based on e.g.
One way to prove this being the cause is by using A1 Website Download. Since all pages are downloaded to disk during crawl, it is possible to inspect the HTML source code of them afterwards.
If you decide to use this program, make sure to enable option Scan website > Data collection > Store redirects, links from and to all pages etc. and possibly also configure Download options, so it does not convert the links for offline browsing.
If you have enabled any of the extended link search options, you may also sometimes have uses that are hard to spot. Some examples:
- Crawler/browser user agent. (Change in General options and tools | Internet crawler).
- Session cookies. (Change in Scan website | Crawler options | Allow cookies).
- Session URLs. (Often used by websites if session cookies are not accepted.)
- Referrer.
- Last viewed page.
One way to prove this being the cause is by using A1 Website Download. Since all pages are downloaded to disk during crawl, it is possible to inspect the HTML source code of them afterwards.
If you decide to use this program, make sure to enable option Scan website > Data collection > Store redirects, links from and to all pages etc. and possibly also configure Download options, so it does not convert the links for offline browsing.
If you have enabled any of the extended link search options, you may also sometimes have uses that are hard to spot. Some examples:
-
Option: Website scan | Crawler options | Search all link tag types
Code:<param name="movie" value="">
Internal Linking and Link Juice
Our website analyzer tool calculates scores for all pages based on internal linking in website.
You can read more about the calculations done by A1 Website Analyzer to determine the page importance. You can also learn more about sculpting your internal link juice.
