|
|

Sprachen, Schriftarten, Unicode und Codepages
A1 Website Search Engine und Informationen zu Schriftarten, Codepages, Zeichensätzen und Unicode, einschließlich z. B. UTF-8
Windows-Systemschriftart und Unicode-Präsentation
Um alle Unicode-Zeichen in Windows XP und darunter korrekt anzuzeigen, müssen Sie möglicherweise Folgendes tun:
Möglicherweise müssen Sie auch sicherstellen, dass alle erforderlichen Unicode-Schriftarten und -Teile installiert sind:

- Ändern Sie die Windows-Systemschriftart in eine vollständige Unicode-Schriftart.
- In der Datei muc.ini (im Installationsverzeichnis des Programms) können Sie unter dem Schlüssel FontOverride steuern, welche Schriftarten A1 Website Search Engine zu verwenden versucht:
[Verschiedenes]
DataAccess=auto
FontOverride=Arial Unicode MS, Lucida Sans Unicode, Segoe UI
Sie können mit den Schriftarten in unterschiedlicher Reihenfolge experimentieren, um die Schriftart zu finden, die Ihnen am besten gefällt.
Möglicherweise müssen Sie auch sicherstellen, dass alle erforderlichen Unicode-Schriftarten und -Teile installiert sind:
Die folgende Hilfe ist hauptsächlich für alte A1-Website-Suchmaschinenversionen relevant
Der Großteil des Inhalts der Hilfeseiten unten wurde im Jahr 2007 geschrieben und ist hauptsächlich für alte Versionen der A1 Website Search Engine relevant
Im Jahr 2010 wurde mit der Veröffentlichung der Version 3.x der A1 -Tools die vollständige interne Unterstützung von Unicode in unserer Website-Suchmaschinensoftware abgeschlossen. Wenn die Unicode-Unterstützung vollständig implementiert ist, müssen Sie Windows normalerweise nicht mehr darüber hinaus konfigurieren.
Hinweis: Die folgenden Dinge gelten jedoch weiterhin für die Version 7.x von 2015 und möglicherweise auch für zukünftige Versionen:
Im Jahr 2010 wurde mit der Veröffentlichung der Version 3.x der A1 -Tools die vollständige interne Unterstützung von Unicode in unserer Website-Suchmaschinensoftware abgeschlossen. Wenn die Unicode-Unterstützung vollständig implementiert ist, müssen Sie Windows normalerweise nicht mehr darüber hinaus konfigurieren.
Hinweis: Die folgenden Dinge gelten jedoch weiterhin für die Version 7.x von 2015 und möglicherweise auch für zukünftige Versionen:
- Die folgenden ausführbaren Dateien werden während der Installation unter Windows hinzugefügt:
- Search_64b_UC.exe / Search_64b_W2K.exe / 64-Bit-Unicode-ausführbare Datei für Windows 2000 oder neuer.
- Search_32b_UC.exe / Search_32b_W2K.exe / 32-Bit-Unicode-ausführbare Datei für Windows 2000 oder neuer.
- Search_32b_CP.exe / Search_32b_W9xNT4.exe / 32-Bit-Codepage ausführbar für Windows 98 / NT4 oder neuer.
- Die für Ihre Computerhardware und Ihr System am besten geeignete wird automatisch als Standard festgelegt.
- Bei der Installation von A1 Website Search Engine unter Windows 95/98/ME/NT4 führt dies zu einer nicht-Unicode-ausführbaren Datei.
Crawlen nicht-westlicher oder fernöstlicher Sprachwebsites
Derzeit ist es möglich, alle einsprachigen (und einige mehrsprachigen) Websites zu scannen. Dazu gehört das Extrahieren von Titeln, Text usw.
Derzeit führt die A1 Website Search Engine beim Scannen Folgendes aus:
Wenn eine Website mehrere Sprachen verwendet, können Sie eine der folgenden Lösungen ausprobieren:
Derzeit führt die A1 Website Search Engine beim Scannen Folgendes aus:
- Stößt auf eine Website, die einen Zeichensatz verwendet, normalerweise UTF-8, UTF-16 oder ISO 8859-1.
Die tatsächlich verwendete Website-Sprache kann beispielsweise Englisch, Deutsch, Arabisch, Russisch, Chinesisch oder ähnliches sein. - Der Website-Text wird in die von Windows konfigurierte Codepage des lokalen Computers konvertiert. Dafür braucht man:
- Der Windows-Codepage-Zeichensatz des lokalen Computers enthält die auf der Website verwendeten Sprachen.
- Die Website verwendet entweder UTF-8, UTF-16 (+ einige mehr) oder die gleiche/ähnliche Codepage wie der lokale Computer.
- Das gesamte Scannen, Verarbeiten usw. von Zeichenfolgen erfolgt in der lokalen Codepage, unabhängig davon, ob es sich um einen Einzel- oder einen Multibyte-codierten Zeichensatz handelt.
- Beim Erstellen von z. B. UTF-8-XML-Dateien wird der gesamte Text in der lokalen Codepage korrekt in UTF-8 konvertiert.
Wenn eine Website mehrere Sprachen verwendet, können Sie eine der folgenden Lösungen ausprobieren:
- Am besten:
- Suchen und verwenden Sie eine Codepage, die alle Sprachen auf der Website unterstützt.
- Alternative:
- Teilen Sie den Website-Scan in mehrere Projekte auf, eines für jede Sprache.
- Stellen Sie bei jedem Website-Scan-Projekt sicher, dass Sie eine geeignete Codepage verwenden.
Gängige Codepages und die darin enthaltenen Sprachen
Es gibt viele Codepages. Einige sind sprachspezifisch. Einige umfassen mehrere Sprachen, meist verwandte Sprachen, z. B. Latein oder Kyrillisch.
- ISO 8859-1: Enthält die meisten westeuropäischen Sprachen. Diese (oder eine etwas andere) Codepage ist die Standardeinstellung der meisten „westlichen“ Windows-Computer.
- Zeichensatz der Codepage Windows-1252: Sehr ähnlich zu ISO 8859-1.
- ISO 8859-2: Enthält viele mittel- und osteuropäische Sprachen.
- Codepage Windows-1250-Zeichensatz: Ziemlich ähnlich zu ISO 8859-2.
- Codepage Windows-1251 Zeichensatz: Enthält kyrillische Sprachen (z. B. Russisch) und Englisch.
- KOI-8: Beliebte russische Codepage. Gut für russische/englische Dokumente.
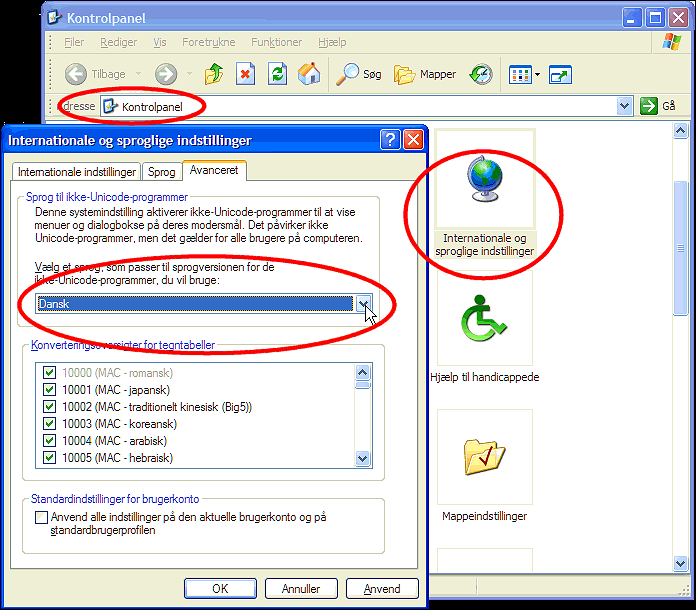
Wechseln Sie die Windows-Codepage-Sprache, die für Nicht-Unicode-Programme verwendet wird
- Öffnen Sie die Systemsteuerung | Regional und Sprache | Fortgeschritten.
- Wählen Sie die Sprache aus, die Sie verwenden möchten, und klicken Sie auf OK.
Wenn die A1-Website-Suchmaschine intern auf Unicode UTF-8 oder UTF-16 umstellt
Wir verwenden derzeit Borland/CodeGear Delphi für die native Windows 32-Bit-Entwicklung. Obwohl wir als langfristiges Ziel die Kompilierung unseres Quellcodes mit mehreren Entwicklertools und Betriebssystemplattformen verfolgen, bleibt Delphi derzeit unser primäres Tool.
Das aktuelle Problem besteht darin, dass Delphi es schwierig macht, vollständige Unterstützung für Unicode zu erhalten, selbst wenn Lösungen von Drittanbietern verwendet werden (von denen sich die meisten nur mit der Steuerung der Benutzeroberfläche und nicht mit der Zeichenfolgenverarbeitung als solche befassen). Ein schwerwiegenderes Hindernis besteht darin, dass heute in Delphi implementierte Unicode-Lösungen Gefahr laufen, ersetzt und überarbeitet zu werden, sobald Delphi Unicode intern in seinen Klassenbibliotheken und seinem nativen String-Datentyp unterstützt.
Wir haben eine fast vollständige Datei- und String-Abstraktionsschicht geschrieben, die Hunderte von Funktionsaufrufen abbildet, breit und spezialisiert. Alle Funktionen verwenden derzeit den nativen Delphi-String-Basistyp. Diese Ebene ändert derzeit einige ihrer Zuordnungen, je nachdem, welche Art von Codepage-Zeichensatzkodierung verwendet wird, Einzelbyte oder DBCS / MBCS.
Wenn Borland/CodeGear seine Unicode-Lösung für die native Windows-Entwicklung implementiert hat, die höchstwahrscheinlich entweder auf UTF-8 oder UTF-16 basiert, werden wir unser String-Abstraktionssystem um dieses erweitern und vollständige interne Unterstützung für Unicode erhalten. Die Schritte hierfür sind:
Darauf haben wir uns schon lange vorbereitet. Wir hoffen jedoch, dass Sie verstehen, dass damit ein großer Arbeits- und Qualitätssicherungsaufwand verbunden ist, und warten daher ab, welchen Weg Borland/CodeGear mit Delphi einschlägt, bevor wir die vielen Arbeitsstunden für die endgültige Lösung aufwenden.
Derzeit sieht die Roadmap für Delphi eine vollständige Unicode-Unterstützung in Delphi „Tiburon“ (Codename) vor, die für das erste Halbjahr 2008 geplant ist. Zu einem späteren Zeitpunkt werden wir die Einzelheiten des Pfads erfahren, den Borland/CodeGear für die Implementierung der Unicode-Unterstützung gewählt hat. Dies bedeutet, dass wir die letzten Schritte der Unicode-Unterstützung höchstwahrscheinlich früher als oben angegeben umsetzen können.
Das aktuelle Problem besteht darin, dass Delphi es schwierig macht, vollständige Unterstützung für Unicode zu erhalten, selbst wenn Lösungen von Drittanbietern verwendet werden (von denen sich die meisten nur mit der Steuerung der Benutzeroberfläche und nicht mit der Zeichenfolgenverarbeitung als solche befassen). Ein schwerwiegenderes Hindernis besteht darin, dass heute in Delphi implementierte Unicode-Lösungen Gefahr laufen, ersetzt und überarbeitet zu werden, sobald Delphi Unicode intern in seinen Klassenbibliotheken und seinem nativen String-Datentyp unterstützt.
Wir haben eine fast vollständige Datei- und String-Abstraktionsschicht geschrieben, die Hunderte von Funktionsaufrufen abbildet, breit und spezialisiert. Alle Funktionen verwenden derzeit den nativen Delphi-String-Basistyp. Diese Ebene ändert derzeit einige ihrer Zuordnungen, je nachdem, welche Art von Codepage-Zeichensatzkodierung verwendet wird, Einzelbyte oder DBCS / MBCS.
Wenn Borland/CodeGear seine Unicode-Lösung für die native Windows-Entwicklung implementiert hat, die höchstwahrscheinlich entweder auf UTF-8 oder UTF-16 basiert, werden wir unser String-Abstraktionssystem um dieses erweitern und vollständige interne Unterstützung für Unicode erhalten. Die Schritte hierfür sind:
- Einige Überarbeitungen und Codierungen unserer String-Abstraktionsschicht. Der Arbeitsaufwand hängt von der Route ab, die Borland/CodeGear wählt, z. B. von der Notwendigkeit einer Konvertierung zwischen Unicode-Typen und dem nativen Delphi-Datentyp „String“.
- Erweitern Sie alle Zeichenfolgenfunktionszuordnungen mit Unicode-Version(en). Der Sinn besteht darin, das Konvertieren und Umschreiben der vielen tausend und doch tausenden Stellen zu vermeiden, an denen diese String-Funktionen aufgerufen werden.
- Auch wenn das oben Gesagte berücksichtigt wird, gibt es viele Codebereiche, die überprüft und geringfügig geändert werden müssen.
- Qualitätssicherung, die viele Tests bedeutet.
Darauf haben wir uns schon lange vorbereitet. Wir hoffen jedoch, dass Sie verstehen, dass damit ein großer Arbeits- und Qualitätssicherungsaufwand verbunden ist, und warten daher ab, welchen Weg Borland/CodeGear mit Delphi einschlägt, bevor wir die vielen Arbeitsstunden für die endgültige Lösung aufwenden.
Derzeit sieht die Roadmap für Delphi eine vollständige Unicode-Unterstützung in Delphi „Tiburon“ (Codename) vor, die für das erste Halbjahr 2008 geplant ist. Zu einem späteren Zeitpunkt werden wir die Einzelheiten des Pfads erfahren, den Borland/CodeGear für die Implementierung der Unicode-Unterstützung gewählt hat. Dies bedeutet, dass wir die letzten Schritte der Unicode-Unterstützung höchstwahrscheinlich früher als oben angegeben umsetzen können.
