|
|

Webstedssøgning efter login-adgangskodebeskyttede sider
Scan og crawl hjemmeside med hjemmesidesøgemaskine, selvom hjemmesiden kræver login brugernavn og adgangskode.
Login Support til HTTPS-websteder
Hvis dit websted bruger HTTPS, skal du muligvis konfigurere A1 Website Search Engine til dette.
For mere information, se denne hjælpeside om https.
For mere information, se denne hjælpeside om https.
Konfigurer altid først: URL-ekskluder filtre
Vigtigt: Hvis du udfører et brugerlogin, er det meget vigtigt at sørge for og verificere dig selv, at crawleren ikke følger links, der kan slette eller ændre indhold.
Du kan gøre dette på to måder:
Bemærk Det er også vigtigt at undgå, at crawleren følger et logout- link, da crawleren ellers vil logge ud af sig selv.
Du kan kontrollere, hvilke URL'er A1 Website Search Engine henter under webstedsgennemgangen ved at ekskludere dem i analysefiltre og outputfiltre.
Sørg for at teste, at dine filtre er konfigureret korrekt og fungerer efter hensigten. Bemærk også , at vi ikke kan tage ansvar, hvis noget går galt - enten med konfigurationen eller i softwaren.
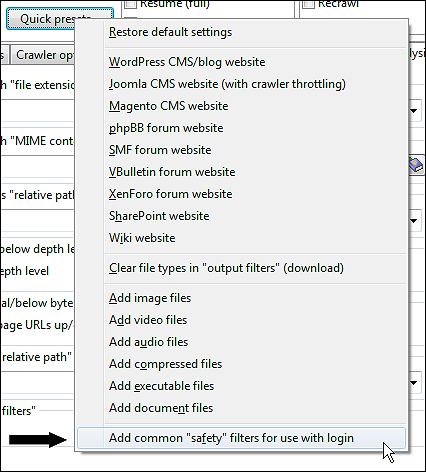
Bemærk: Der er en forudindstilling tilgængelig på Scan-webstedet | Hurtige forudindstillinger... der kan hjælpe med at udelukke nogle almindelige mønstre af uønskede URL'er:
Du kan gøre dette på to måder:
- Har en brugerkonto, der ikke kan redigere eller slette noget indhold eller indstillinger. ( Sikkert .)
- Begræns crawleren til ikke at følge nogen uønskede links. ( Usikkert .)
Bemærk Det er også vigtigt at undgå, at crawleren følger et logout- link, da crawleren ellers vil logge ud af sig selv.
Du kan kontrollere, hvilke URL'er A1 Website Search Engine henter under webstedsgennemgangen ved at ekskludere dem i analysefiltre og outputfiltre.
Sørg for at teste, at dine filtre er konfigureret korrekt og fungerer efter hensigten. Bemærk også , at vi ikke kan tage ansvar, hvis noget går galt - enten med konfigurationen eller i softwaren.
Bemærk: Der er en forudindstilling tilgængelig på Scan-webstedet | Hurtige forudindstillinger... der kan hjælpe med at udelukke nogle almindelige mønstre af uønskede URL'er:
Hjemmesideloginmetode: Integreret Windows Internet Explorer / Edge
Dette er den nemmeste login-metode at bruge, da den kræver den mindste konfiguration. Det virker dog kun på Windows.
In Scan hjemmeside | Crawler-motoren vælger HTTP ved hjælp af Windows API WinInet.
Hver gang du vil starte webstedsscanningen, skal du gøre følgende:

Denne kombination vil sikre, at A1 Website Search Engine har adgang til alle cookies, der overføres under login. Du kan nu starte scanningen af hjemmesiden.
Bemærk, hvis du ikke brugte det normale installationsprogram: Når du bruger Internet Explorer i indlejret tilstand, vil det ifølge Microsofts design som standard opføre sig som en ældre version. Dette kan forårsage problemer med nogle få websteder. For mere info se dette blogindlæg på MSDN.
In Scan hjemmeside | Crawler-motoren vælger HTTP ved hjælp af Windows API WinInet.
Hver gang du vil starte webstedsscanningen, skal du gøre følgende:
- Fyld Scan hjemmeside | Stier | Hjemmesidens domæneadresse først, da det gør det næste skridt nemmere.
- In Scan hjemmeside | Crawler login klik på knappen Åbn integreret browser og log på før crawl.
- Afhængigt af programversionen: Klik på knappen Kopier sessionscookies, hvis de er tilgængelige.
- Naviger til login-sektionen på hjemmesiden, og log ind som du normalt ville.
- Du kan nu lukke det integrerede browservindue.
Denne kombination vil sikre, at A1 Website Search Engine har adgang til alle cookies, der overføres under login. Du kan nu starte scanningen af hjemmesiden.
Bemærk, hvis du ikke brugte det normale installationsprogram: Når du bruger Internet Explorer i indlejret tilstand, vil det ifølge Microsofts design som standard opføre sig som en ældre version. Dette kan forårsage problemer med nogle få websteder. For mere info se dette blogindlæg på MSDN.
Hjemmesideloginmetode: Protokolbaserede login- og autentificeringsmetoder
Der er nogle andre populære login-mekanismer, som bruger etablerede protokoller i stedet for at lade webstedet håndtere det. Disse kaldes NTLM, SSPI, Digest og Basic Realm Authentication. Selvom understøttelse af nogle af disse loginmetoder stadig er i gang, kan de nogle gange bruges til webstedslogin.
Du kan genkende websteder, der bruger dette via login-dialoger som denne:

Det er meget nemt at konfigurere crawleren i vores webstedssøgemaskinesoftware til denne loginmetode Scan websted | Crawler login :

For at bruge ovenstående vil du typisk bruge HTTP ved hjælp af Indy-motoren til internet og localhost- indstillingen i Scan hjemmeside | Crawler motor | Standard stitype og -handler, men hvis det mislykkes, kan du også prøve HTTP ved hjælp af Windows API WinInet- indstillingen og logge på med den indlejrede browser, før du starter webstedscrawlet.
Du kan genkende websteder, der bruger dette via login-dialoger som denne:
Det er meget nemt at konfigurere crawleren i vores webstedssøgemaskinesoftware til denne loginmetode Scan websted | Crawler login :
For at bruge ovenstående vil du typisk bruge HTTP ved hjælp af Indy-motoren til internet og localhost- indstillingen i Scan hjemmeside | Crawler motor | Standard stitype og -handler, men hvis det mislykkes, kan du også prøve HTTP ved hjælp af Windows API WinInet- indstillingen og logge på med den indlejrede browser, før du starter webstedscrawlet.
Hjemmeside Login Metode: Post Form / Session cookies
Historisk set er POST-formularlogin blevet testet mest med HTTP ved hjælp af Indy-motoren til internet og localhost- indstillingen i Scan-webstedet | Crawler motor | Standard stitype og handler.

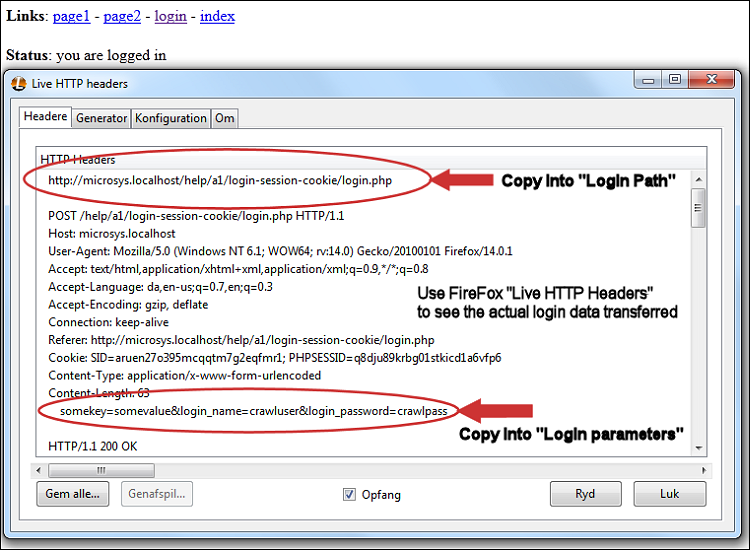
For at bruge denne løsning skal du forstå, hvilke data der sendes, når du logger på et websted, så du kan konfigurere A1 Website Search Engine til at sende det samme. Du kan bruge et FireFox- plugin kaldet Live HTTP Headers til at se de overskrifter, der overføres under login-processen:
Hent FireFox Live HTTP Headers plugin:
Når du har gjort det, kopierer og indsætter du bare de relevante værdier i A1 Website Search Engine-loginkonfigurationen:

Hvis du leder efter et alternativ til FireFox Live HTTP Headers, kan du tjekke Fiddler (til Internet Explorer) og WireShark (generelt værktøj).
For at bruge denne løsning skal du forstå, hvilke data der sendes, når du logger på et websted, så du kan konfigurere A1 Website Search Engine til at sende det samme. Du kan bruge et FireFox- plugin kaldet Live HTTP Headers til at se de overskrifter, der overføres under login-processen:
Hent FireFox Live HTTP Headers plugin:
- Ryd alle allerede indsamlede HTTP-headere.
- Prøv at oprette et webstedslogin i Firefox-browseren.
- Fokuser nu på de loggede HTTP-headerdata fra den første indgang/side.
- Bemærk den webstedsadresse, FireFox opretter forbindelse til.
- Læg mærke til indholdet (POST-dataforespørgselsstrengen), den sender.
- Brug disse data til at konfigurere overskrifter til at sende.
Når du har gjort det, kopierer og indsætter du bare de relevante værdier i A1 Website Search Engine-loginkonfigurationen:
Hvis du leder efter et alternativ til FireFox Live HTTP Headers, kan du tjekke Fiddler (til Internet Explorer) og WireShark (generelt værktøj).
Hjemmesidelogin - Indlægsformular / Sessionscookies: Detaljer og demoprojekt
Vi har lavet et demoprojekt, der tester crawler-login-support for websteder, der bruger sessionscookies.
Sessionscookies er den mest almindeligt anvendte metode til hjemmesideloginsystemer. De fleste af disse webstedslogin bruger POST-metoden til at overføre login- og brugerdata. Det er, hvad PHP er standard til, når du bruger start_session.
Du kan online teste eller downloade zippet demo-websted med login-support. For øjeblikkelig test, download også den zippede demoprojektfil.
Det brugernavn og den adgangskode, der kræves for at logge ind, er fremhævet på login- siden.
Sessionscookies er den mest almindeligt anvendte metode til hjemmesideloginsystemer. De fleste af disse webstedslogin bruger POST-metoden til at overføre login- og brugerdata. Det er, hvad PHP er standard til, når du bruger start_session.
Du kan online teste eller downloade zippet demo-websted med login-support. For øjeblikkelig test, download også den zippede demoprojektfil.
Det brugernavn og den adgangskode, der kræves for at logge ind, er fremhævet på login- siden.
- Test først manuelt at login-support virker:
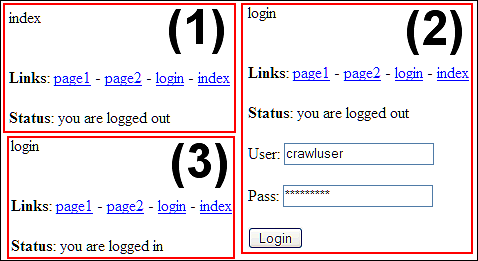
Læg mærke til, hvordan alle sider efter login angiver, at brugere er logget ind. - Vi konfigurerer webstedscrawl-rodmappen:

Dette gøres på Scan hjemmeside | Stier. - Vi tjekker kilden til login-siden:

- Du kan se kilde i f.eks. FireFox.
- Søg efter <form>- og <input> -tags relateret til webstedslogin.
- Hvis URL'en i <form> -taghandlingsattributten er tom, betyder det, at handlingens destinations-URL er den samme som URL'en til loginsiden.
- Navneattributten i <input> tags varierer fra websted til websted.
- Vi konfigurerer login mulighederne:
Dette gøres på Scan hjemmeside | Crawler identifikation. - Vi er nødt til at bortfiltrere alle webadresser, der vil forårsage webstedslogout under crawl:

Dette gøres på Scan hjemmeside | Analysefiltre og Scan hjemmeside | Udgangsfiltre. - Start hjemmesidescanning. En nem måde at teste og verificere login fungerer på er ved at bruge A1 Website Download. Bare se de downloadede sider: De skal alle angive logget ind.
Hjemmesidelogin - Postformular/sessionscookies: Kendte problemer og problemer
Loginsystemer og koncepter, der vides at forårsage problemer:
Ovenstående gør det næsten umuligt at få webstedssøgemaskinelogin til at fungere korrekt, medmindre du har direkte adgang til webstedet og kender det indre udmærket.
Kendte systemer, der forårsager problemer:
- Ved første login sendes en unik beregnet værdi i login-formularen: Eksempel kunne være Javascript-kode, der baseret på f.eks. nøjagtigt tidspunkt, IP-adresse, browser-brugeragent-id etc. beregner en værdi (f.eks. en hash eller lignende) sendt i login-form. Serveren kender den algoritme, som værdien blev genereret med, og validerer den på serversiden.
Ovenstående gør det næsten umuligt at få webstedssøgemaskinelogin til at fungere korrekt, medmindre du har direkte adgang til webstedet og kender det indre udmærket.
Kendte systemer, der forårsager problemer:
- Nogle ASP.Net login formularer
Du kan identificere ASP.Net login-formularer ved at søge i HTML-outputtet efter strengen: name="__VIEWSTATE".
Ren spekulation og igangværende arbejde :
Muligvis bliver "viewstate" ukorrekt, selv når man kopierer hele POST/data/headere overført under manuel login (og kopieret ved hjælp af f.eks. FireFox Live HTTP Headers). En mulig forklaring er, at "viewstate" indeholder en "hash"-lignende verifikationsværdi meget som forklaret ovenfor om problematiske login-systemer.
Alternativ til at crawle login-baserede websteder
Hvis du ejer webstedet, kan du kode det på en måde, der giver fuld adgang til crawlere med specifikke brugeragentstrenge.
Du kan konfigurere dette i Generelle muligheder og værktøjer | Internet-crawler | Brugeragent-id :
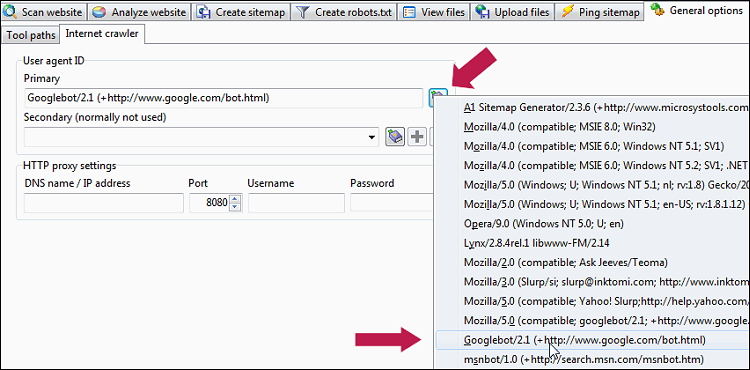
Du kan konfigurere dette i Generelle muligheder og værktøjer | Internet-crawler | Brugeragent-id :
