|
|

Gencrawl og genoptag crawl i Website Scraper
Nogle webservere er træge eller nægter adgang til ukendte crawlere som A1 Website Scraper. For at sikre, at alt bliver gennemgået, kan du bruge "genoptag"-funktionalitet i webstedsskraberværktøjet.
Genoptag scanning for at rette URL'er med fejlsvarkoder
Der kan være mange grunde til at genoptage en hjemmesidescanning, efter at den er stoppet. En af dem er webservere, der typisk kan overbelaste og reagere med fejlkoder til URL'er
En nem måde at afgøre, om der er fejl på hele webstedet, er at se biblioteksoversigten for rodmappen/domænet.
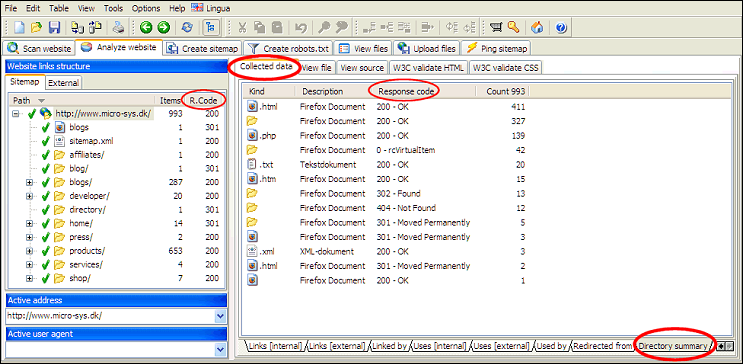
Brug derefter CV- funktionaliteten i A1 Website Scraper til at crawle disse URL'er igen. Fortsæt med at gøre det, indtil der ikke er nogen fejl tilbage.

Mens webstedsscanningen kører, kan du til enhver tid:
Sådan bruger du funktionaliteten til scanning og crawl af websteder:
- 503 : Tjenesten midlertidigt utilgængelig
- 500: Intern serverfejl
- -4 : CommError
En nem måde at afgøre, om der er fejl på hele webstedet, er at se biblioteksoversigten for rodmappen/domænet.
Brug derefter CV- funktionaliteten i A1 Website Scraper til at crawle disse URL'er igen. Fortsæt med at gøre det, indtil der ikke er nogen fejl tilbage.
Mens webstedsscanningen kører, kan du til enhver tid:
- Sæt scanningen på pause, og stop den.
- Genoptag og fortsæt din hjemmesidescanning.
Sådan bruger du funktionaliteten til scanning og crawl af websteder:
- At standse en scanning er det samme som at stoppe en scanning. Hvis scanningen er stoppet/pause eller internet afbrydes, kan du genoptage.
- For at genoptage en scanning skal du markere indstillingen Genoptag. (I gamle versioner var dette en trykknap .) Klik derefter på knappen Start scanning.
- Du kan gemme projektet. Dette giver dig mulighed for at indlæse projektet på et senere tidspunkt. Så kan du genoptage projektet.
Hvorfor midlertidigt pause i webstedscrawl fjernes nogle gange URL'er
Du kan gennemtvinge gencrawl af visse webadresser ved at ændre deres tilstandsflag i webstedsanalyse, før du genoptager webstedsscanningen.
Afhængigt af programmet og versionen er standardadfærden, efter at en hjemmesidescanning er afsluttet af en eller anden grund, f.eks. at være sat på pause, at alle URL'er, der er udelukket af webmasterfiltre, såsom robots.txt- fil og outputfiltre, fjernes.
Ovenstående adfærd er ikke altid ønsket, da det betyder, at webstedscrawleren vil bruge tid på at genfinde URL'er, den har testet før. At løse:
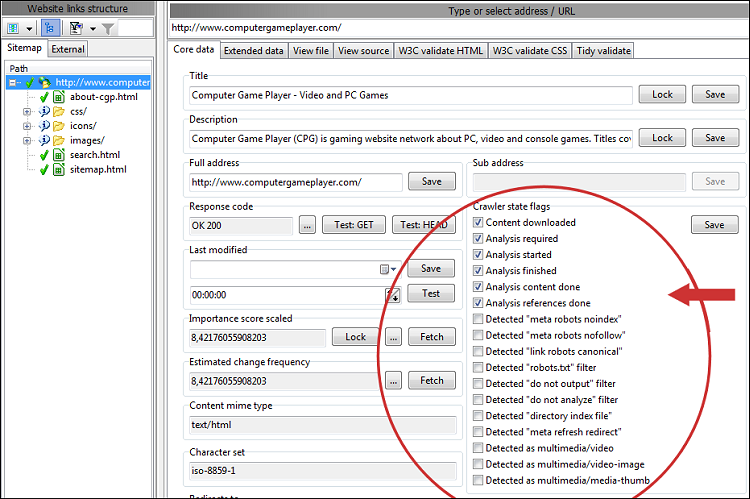
Når filtrerede/ekskluderede URL'er ikke fjernes i webstedsscanningsresultaterne, kan du se deres Crawler- og URL-statusflag :
Afhængigt af programmet og versionen er standardadfærden, efter at en hjemmesidescanning er afsluttet af en eller anden grund, f.eks. at være sat på pause, at alle URL'er, der er udelukket af webmasterfiltre, såsom robots.txt- fil og outputfiltre, fjernes.
Ovenstående adfærd er ikke altid ønsket, da det betyder, at webstedscrawleren vil bruge tid på at genfinde URL'er, den har testet før. At løse:
- Ældre versioner:
- Fjern markeringen i Scan websted | Crawler muligheder | Anvend "webmaster"- og "output"-filtre, efter at webstedsscanningen stopper
- Nyere versioner:
- Fjern markeringen i Scan websted | Udgangsfiltre | Når webstedsscanningen stopper: Fjern ekskluderede webadresser
- Fjern markeringen i Scan websted | Webmaster filtre | Efter at webstedsscanningen stopper: Fjern URL'er med noindex/disallow
Når filtrerede/ekskluderede URL'er ikke fjernes i webstedsscanningsresultaterne, kan du se deres Crawler- og URL-statusflag :
Genoptag webstedsscanning analyserer URL'er igen
Den måde hjemmesidens crawl fungerer internt på, har vi:
Det betyder, at alle sider, hvor alle links ikke er blevet løst, skal analyseres igen, når scanningen genoptages. For at undgå dette problem kan webstedscrawleren bruge HEAD- anmodninger til hurtigt at løse links til verificerede URL'er. Selvom dette forårsager nogle ekstra anmodninger under gennemgang til serveren (omend alle lys ), vil det minimere spild til næsten nul, når du bruger genoptag-funktionalitet.
For at konfigurere dette skal du deaktivere : Scan websted > Crawlermotor > Standard til GET for sideanmodninger
- Fundne URL'er: Dette er URL'er, der er blevet løst og testet.
- URL'er til analyseret indhold: Indholdet af disse URL'er (sider) er blevet analyseret.
- Analyserede referencer URL'er: Links fundet i indholdet af disse URL'er (sider) er blevet løst.
Det betyder, at alle sider, hvor alle links ikke er blevet løst, skal analyseres igen, når scanningen genoptages. For at undgå dette problem kan webstedscrawleren bruge HEAD- anmodninger til hurtigt at løse links til verificerede URL'er. Selvom dette forårsager nogle ekstra anmodninger under gennemgang til serveren (omend alle lys ), vil det minimere spild til næsten nul, når du bruger genoptag-funktionalitet.
For at konfigurere dette skal du deaktivere : Scan websted > Crawlermotor > Standard til GET for sideanmodninger
Gennemtving gencrawl af visse webadresser
Hvis du ikke ønsker at crawle hele webstedet igen, men Resume er ikke relevant, fordi alle webadresser er blevet analyseret, kan du gøre følgende:
- I venstre side, hvor alle webadresser er angivet, skal du vælge dem, du vil have crawlet igen.
- I Crawler State Flags fjern markeringen af alle Analysis xxx flag undtagen Analysis required.
- Klik på knappen Gem i området Flag i Crawlertilstand.
- I Scan hjemmesiden tjek Resume (fuldt).
- Start scanningen.
Find flere URL'er i webstedsscanninger
Hvis du har problemer med at få alle webadresser inkluderet i webstedscrawl, er det vigtigt først at følge ovenstående anbefaling. Årsagen er, at URL'er med fejlsvarkoder ikke crawles for links. Ved at løse det problem vil du som regel også ende med flere URL'er.
Du kan finde flere forslag og tips i vores artikel om hjælp til webcrawl.
Du kan finde flere forslag og tips i vores artikel om hjælp til webcrawl.
Genoptag fuld versus genoptag Fix fejl versus gencrawl
- CV (fuldt) :
- Beholder alle URL'er fra tidligere scanning.
- Vil gennemgå og analysere alle webadresser, der ikke er markeret som fuldt analyserede.
- Hvis der findes nye webadresser, vil disse også blive crawlet.
- Genoptag (ret fejl) :
- Beholder alle URL'er fra tidligere scanning.
- Vil teste alle URL'er, der på en eller anden måde fejl reagerede under crawl.
- Gencrawl (fuld) - også kaldet Opdater :
- Beholder alle URL'er fra tidligere scanning.
- Vil gennemgå og analysere alle URL'er. Dette inkluderer webadresser, der ikke inkluderer analyse, der kræves i deres crawltilstandsflag.
I fremtiden er det muligt, at gencrawlet vil prioritere URL'er ud fra fx vigtighed, hvornår sidst kontrolleret, hvor ofte sideskift mv. - Hvis der findes nye webadresser, vil disse også blive crawlet.
- Nyttigt i tilfælde, hvor du har låst indhold, f.eks. sidetitel for en bestemt URL, og vil sikre dig, at de låste data opbevares.
Brug låseknapperne ved siden af forskellige data, såsom titler.
- Gengennemgang (kun angivet) :
- Kan lide Recrawl, men vil ikke analysere eller inkludere nye webadresser i scanningsresultater.
- Ingen af ovenstående muligheder er markeret:
- Standard og anbefales i de fleste tilfælde.
