|
|

TechSEO360 Crawl finder ikke alle webadresser
Hvad skal du gøre, hvis du kun ser få links efter webstedscrawl af teknisk SEO-program.
Når TechSEO360-programmet finder for få eller ulige side-URL'er
Læs først, hvordan TechSEO360 hjælper med at finde problemer med webstedslinks. Gennemgå derefter denne tjekliste:
- Bruger du et firewall- program? Du skal konfigurere det, hvis webstedsscanning returnerer få URL'er, og de alle har svarkode -4 : CommError.
- Blander du www- og ikke-www- brug i webstedslinks og omdirigeringer? Tjek eksternt faneblad for at vide.
- Bruger dit websted website-cloaking, dvs. ændre indhold afhængigt af den brugeragentstreng, der bruges af crawleren? Skift derefter brugeragentstrengen, der bruges af crawleren til at identificere sig selv: Generelle muligheder og værktøjer | Internet-crawler | Brugeragent-id.
- Omdirigerer dit websted og/eller sider på det til eller får indhold fra et andet domæne? (f.eks. gennem <frame> eller <iframe> ) Tjek eksternt faneblad for at vide det.
- Er et helt afsnit af sider skjult og slet ikke linket fra de andre dele af hjemmesiden? I dette tilfælde er det ingen hjælp at have krydslinket alle skjulte sider! For at løse dette kan du bruge flere startsøgestier.
- Er webstedet afhængigt af Javascript eller usædvanlige typer HTML-linktags til webstedsnavigation, f.eks. <iframe>, <form> og <button> ? Løsning: Aktiver kontrol af disse ting for links på Scan-webstedet | Crawler muligheder.
- Bruger hjemmesiden // i stedet for / i links? Og reagerer webserveren ikke med en fejl eller omdirigering i sådanne tilfælde? Og falder problemet sammen, hvis sidens URL linkes ved hjælp af relative stier? Løsning: Konfigurer Scan-webstedet | Crawler-muligheder til at håndtere denne situation.
- Har hjemmesiden en dynamisk side, der genererer unikke links baseret på input fra GET? data? Dette kan nogle gange forårsage en endeløs løkke af unikke URL'er!
- Forskellige ekskluderingsfiltre i programkonfiguration og websted:
- Blokerer du sider med robots.txt eller noindex- metatags? Lær mere om nofollow, noindex og robots.txt.
- Har du konfigureret analyse til at udelukke bestemte URL'er og outputfiltre og glemt dem?
Husk: Hvis du ekskluderer nogle side-URL'er fra analyse, finder eller følger crawleren ikke linkene på disse sider. Hvis du har URL'er, der ellers ikke er linket fra nogen steder - vil disse URL'er aldrig blive fundet eller analyseret.
Du kan også konfigurere, hvornår URL'er udelukkes af Scan websted | Outputfiltre, robots.txt og lignende fjernes:- Ældre versioner:
- Scan hjemmeside | Crawler muligheder | Anvend "webmaster"- og "output"-filtre, efter at webstedsscanningen stopper
- Nyere versioner:
- Scan hjemmeside | Udgangsfiltre | Når webstedsscanningen stopper: Fjern ekskluderede webadresser
- Scan hjemmeside | Webmaster filtre | Efter at webstedsscanningen stopper: Fjern URL'er med noindex/disallow
Deaktivering af ovenstående gør det nemmere at finde mulige årsager til manglende URL'er. Du kan se mange detaljer i sektionen Crawler og URL-tilstandsflag for hver URL. Hvis du stadig har problemer med at finde ud af, hvorfor en side-URL mangler, prøv at undersøge hele linkkæden ved at inspicere flagene for noindex, nofollow, disallow og lignende. Du vil måske også inspicere HTML-kilden for at kontrollere, at links er kodet korrekt.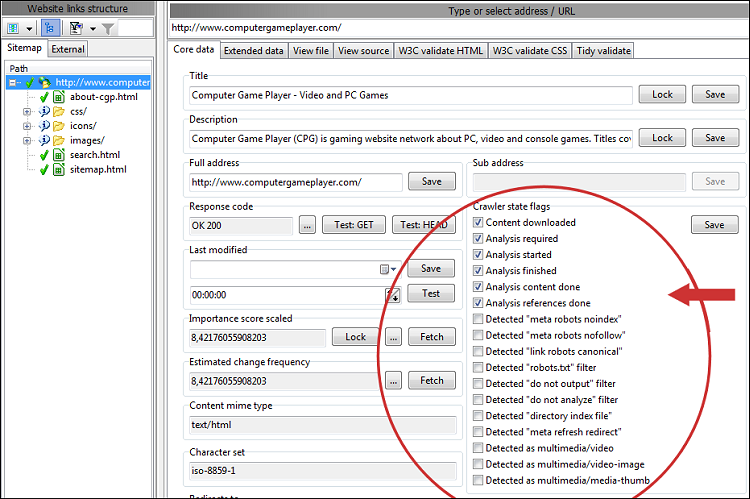
- Scanner du et websteds underbibliotek, som ikke indeholder links til sider i det katalog? Tjek eksternt faneblad for at vide.
- Overvej om dit websted bruger ikke-standard filtypenavne. Hvis du ved hvilke, kan du tilføje dem:

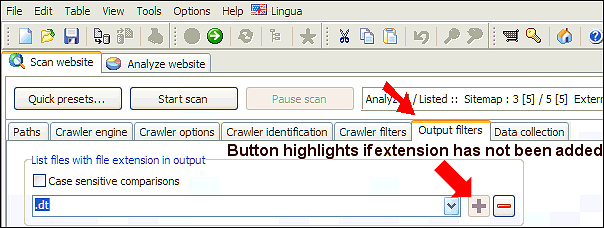
Alternativt kan du rydde alle filtypenavne i analyse- og outputfiltre, men beholde standard MIME- filtre begge steder. Prøv derefter at scanne igen. - Har du mapper med svarkode 0: VirtualItem i scanningsresultater? Tjek oplysningerne om links til internt websted.
- Er der mange URL'er med fejl i webstedsscanningsresultaterne? Hvis webserveren får nogle URL'er til at give fejlsvarkoder, f.eks. på grund af serverens båndbredderegulering, kan du prøve at genoptage scanningen, indtil alle fejl er væk. Dette vil højst sandsynligt føre til flere fundne links og sider.
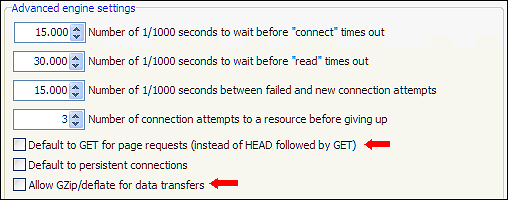
En anden løsning til at løse URL'er med fejlsvar er at eksperimentere med muligheder, der findes på Scan-webstedet | Crawler motor | Avancerede motorindstillinger. Nogle almindelige indstillinger, som ofte hjælper: Forøgelse af timeout- værdier, brug af kun GET og aktivering/deaktivering af GZip/defalte -understøttelse.